We can't find the internet
Attempting to reconnect
Something went wrong!
Attempting to reconnect
Ruby on Rails · 673 views · 15 likes
Analysis Summary
Worth Noting
Positive elements
- This video provides valuable, practical insights into the 'un-hyped' reality of maintaining a decade-old SaaS platform, specifically regarding the costs of technical debt and the benefits of architectural simplification.
Influence Dimensions
How are these scored?About this analysis
Knowing about these techniques makes them visible, not powerless. The ones that work best on you are the ones that match beliefs you already hold.
This analysis is a tool for your own thinking — what you do with it is up to you.
Related content covering similar topics.

Alexander Stathis: Scaling a Modular Rails Monolith at AngelList
Ruby on Rails

Miguel Conde & Peter Compernolle: Inside Gusto’s Rails Biolith
Ruby on Rails

Behind the Fizzy Infrastructure with Kevin McConnell
37signals
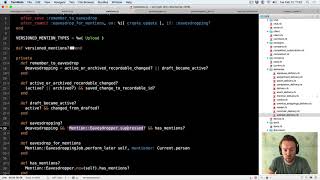
On Writing Software Well #2: Using callbacks to manage auxiliary complexity
David Heinemeier Hansson

Most founders dream they'll get to problems at scale #rails #rubyonrails
Ruby on Rails
Transcript
[music] Welcome to On Rails, the podcast where we dig into the technical decisions behind building and maintaining production Ruby on Rails apps. I'm your host, [music] Robbie Russell. In this episode, I'm joined by Jay Tenier, engineering manager at Rainforest QA. Jay's been there for a little over 7 years working across a long live Rails monolith, a [music] handful of supporting services, and a front end powered by React and Grape APIs. Over that time, he's seen the platform and the team grow, shrink, refactor, reap, backtrack, simplify, and occasionally reinvent itself. Jay brings a practical perspective on what it takes to keep a mature Rails app moving. Hiring in different stages of company growth, taming legacy endpoints, deciding when to pull back microservices back into the monolith, offloading [music] analytics to things like BigQuery, and figuring out how a small team survives all of it. We'll dig into the technical decisions behind those choices, and what other teams might take away from Rainfor's journey. Jay joins us from Ontario, Canada. All right, check for your belongings. All aboard. Jay Ten, welcome to On Rails. >> Thanks for having me. >> All right, Jay, let's start with this really hard question. What keeps you on Rails? >> H, [sighs] it's a good question. Um, I mean, I guess there's two sides to it, right? There's the personal one. Personally, I'm still on Rails because I love Rails. been gez I've been developing with Rails for oh since what.13 I think yeah somewhere way back there my real first app was in like version two but there's just something about Rails that has always kind of suited my head once I kind of wrap my head around it and I mean the other thing too is I just love Ruby tried a few other things been writing in Python lately and it's just it's cool right nothing wrong with it but yeah there just something about the the way the Ruby is that I really really like. And then from the rainforest perspective, we are on rails because we've always been on rail. Well, I shouldn't say always, but for a very very long time, we've been on rails. And decision was made not by me, by my previous boss about I think about eight years ago. And uh the decision was we're hiring people to work with Rails. We have a bunch of people who work with Rails. So unless there's a really good reason not to use Rails, we should use it because just to keep everybody on the same page, nobody having to learn anything else. And that kind of went with Ruby, too, where it was if we had any kind of side stuff that we needed to do, we're going to keep using Ruby for that. And I mean, there's a couple things that we didn't use it for that made sense, like our CLI is written in Go. But it really panned out because we we do have a service that's an Erlang and all of those people have left and now nobody knows what to do with it. And then we had kind of like a side project that somebody wanted to try out Phoenix and same thing those people left and it's just anybody know Phoenix and nobody does right. So sticking on Rails has just been kind of like the the mantra for Rainforest for a long time. >> Nice. And we'll dig into your Rainforest stack in in a moment. I'm curious about, you know, you mentioned been using Rails since, you know, 13 or so. I think that's pretty much around I think I might have barely [clears throat] beat you by like 12 and that was probably like what, a month apart or something like that. So, give or take. Out of curiosity, what tech stacks or tooling were you working with prior to that? >> Back then, that was PHP and hand rolled. Yeah, hand rolled an app. I took over an app that was a like an employee satisfaction survey app that was written by a student in PHP and so it was just kind of taking that extending it out and then from that point I mean that was back in the slash days coming across all this new cool stuff and Rails kind of showed up and I wasn't able to really use it >> sure >> at that job because I was the only developer I couldn't stop doing what I was doing in order to do that but I had a little side project that I spun up with Rails to I want to say it was like an internal time tracking app for myself and then wrote some Ruby code, some glue code kind of thing back then. But yeah, it was PHP and then that was when Cake was out and Cake was kind of doing the same thing and then I got it in my head that I could rewrite the uh survey app in an MVC style. So I started digging into the Rails codebase and was trying to do similar things setting up like controllers and how views would work and delaying content rendering and learned a lot too much probably [laughter] um because then it was a typical like I got half of the code base moved over to that and then the other half wasn't there but luckily I left that to somebody else. [laughter] >> I can appreciate that and I think that resonates with some of my earlier projects pre- Rails as well. So for our listeners who may not be familiar with Rainforest QA, can you give us kind of a high level overview of the product platform and where Rails fits into it today? >> Yeah. So Rainforest QA is a SAS platform lets pretty much anybody with a SAS app test their app at the highest level possible which is like in the browser. So most people I think are familiar with Playright or Selenium headless testing that kind of thing. But we don't give you that. We give you a user interface to go in create your clicks and your fills and your observes and that kind of stuff. And then we execute the test that you have written using a VM which we drive so that you've got basically a real mouse clicking around on real elements. We have some like DOM fallbacks and that kind of stuff for those people who need it. We're kind of the belief that trying to find the actual images of things on the page is a little more resilient than just, you know, hard-coded DOM ids and then interacting with them in that way. And the other thing, too, is because it's a VM, you're not trapped in the browser. You have access to the entire OS if you want. So, we have a lot of companies who need to install an app and test the app in concert with their actual like SAS app. So they can do that because you're just basically interacting with the VM, right? So it's uh I see. Yeah, it's pretty nice. And then um it's generally that way. We've got an automated service and then we also have a tester driven service which is uh using humans to execute your tests. So you can write out a different set of steps that are a little more loose that a human would understand and you can execute those things too. Then we've got a whole AI thing going on right now [laughter] as well. >> Interesting. So, we're not trying to necessarily plug Rainforest or anything as like everybody should go use this platform or whatever, but the typical user or customer, is it like a QA team that's like setting setting up things for like within a product team? Or is it a bunch of typically a bunch of new engineers that are trying to do away with needing to have some human QA people that are going around clicking things on their staging environment before things go to production or is this used for a lot of like smoke testing or a little bit of all of the above? >> It's kind of all of the above. Yeah, smoke testing is a big thing. We use it as our like last stop gap before we release, but we have some clients who are who don't have a QA team and so they're getting the devs to drive it. That's I think where we prefer to be right now, but we also have QA teams that are using it as they set up their automated tests and then they drive it out. We've, you know, we dabbled in the like pure no code space for a while. So it was trying to get the like product owners to write those things rather than the devs because our UX is pretty good for doing that kind of thing. So yeah, we're kind of at all of those levels kind of thing. But yeah, I think we're we're kind of going after developers right now. >> I see. That makes sense. We had a previous conversation leading up to this and you mentioned that Rainforest primarily has a monolith, right? And is you're are using React on the front end like what other and you you already also mentioned Go and Erling a couple of other tools in your overall platform. Can you kind of walk us through what that whole ecosystem looks like today? Then we can dive a little bit back where it used to be and how it got to where it is today. >> Yeah. So the main app, if you do use Rainforest, you're going to be looking at the monolith which provides all the backend. The Rails monolith on that side and then the UI is a separate React app. And then we have a couple separate services that I wouldn't call them microservices. They never really started as microservices I don't think. The main one being what we call V manager which is our VM manager. And that is another Rails app and it's responsible purely for making sure that all the VMs that we have are available and setting them up, tearing them down. There's a lower level service written in Ruby that kind of sits closer to the OS called VControl that takes care of the actual nuts and bolts of setting all of that up. So if you open up a test and you need a VM, we talk to V manager. V manager talks to VC control and then it comes kind of back up. And yeah, we've got an Erlang service and that is mainly for the tester community. It's what we use to like set up jobs. Our testers come online, they have a uh a browser extension and they're like I'm available for work. And so we have this Erlang services is just there to kind of mediate between testers and the jobs that we want to give them. And then we've got a like a CLI and that was written in Go because we need to support it on every platform. >> Sure. Sure. That makes sense. And when the say your VM manager spins up a VM where does that spin up using you have your own hardware doing this AWS some other platforms or >> we rent server space in lease web in the states and hner in Germany. We started in we started in Germany a long time ago and that presents its own problems where you start up a VM and you go to Google and everything's in German. So we've had to we've had to do a bunch of stuff to kind of get around that proxying through different places like Oh, interesting. >> Yeah, in most cases it doesn't matter, but if you want to actually if you're just testing your own app, but if you're trying to like go out to the wider uh internet, it does uh it does make a difference. But yeah, so we've got a bunch of servers there. VControl runs on those servers. make sure that those servers have say I don't know what the actual number is but like we've got 200 servers and maybe we've got 20 VMs on each of those servers and we try and make sure that like we've got enough Windows 10 over here and Windows Chrome versus Windows uh Firefox versus Mac OS that kind of thing. So we've got those kind of all sitting there and then mainly we we spun up the ones in the US so that we could have them closer to most of our users. When we're executing your test suite, doesn't matter where it is in terms of like latency, but when you're using the app and writing your test and directly connected to that VM, we want it to be as snappy as possible. So, we bought some servers over there to move them closer. >> And how different is running like say a a suite of QA tests in this context different than running like a bunch of headless tests on your like local computer or in a CI server where you can in theory try to do a bunch of things in parallel. Is this still a lot of paralization happening for >> Yeah. Yeah. When you create a run, um a run for us is just like a like the set of tests, right? Um that you want to uh want to execute. And so we just go out and say get me whatever we need as many of yeah Windows Chrome VMs as you've got and they're kind of running wherever. There are certain things that clients need to do special things, right? whether it's like using different proxies and that kind of stuff to kind of winnow down the VMs that are available to them. But in terms of your general just like we're going to run something in Windows 11 Chrome, we've got a bunch of them. So you kick it off and we just go and get as many as we can. >> Oh, I see. >> We've got a little bit of concurrency baked in now because people were obviously eating all of the resources. [laughter] You can kind of have everything if you want. And then we also found that a lot of clients don't want you hitting their site with 200 tests all at the same time. They want to lock that concurrency down as well. >> When you do parallelize those types of things, does it then like I say if if there's a lot of tasks that are like that is trying to repeat that require you to log in, is it then having to go through if you spin up 20 things in parallel? Is it logging in 20 times in parallel and then running just one slightly different test on each of those login? And so is that getting into any interesting tech? You you just mentioned that maybe some of your customers don't want you to have or don't want it to like oversaturate it with too much at the same time, but like might there be some interesting technical decisions like well we're only allowed to have so many users with the same login log into the app at the same time. How did that stuff get split up? >> Yeah, that's always an issue with our clients and it's when you're thinking about it as like a developer, it all just makes sense, right? Oh, we'll just seed QA with all of the correct stuff and it's fine. they could all log in at the same time and all of their data will be completely separate and then you run into the real world of clients and they're like we don't have a QA environment or we don't have a way of re seeding data all the time. Some of them have structured things in a way where you know they can clean things out afterwards. Others are doing the seating as part of the tests which is crazy because it adds a bunch of time to test. other clients are trying to restrict it down so that basically one user is logging in at a time and each of the tests kind of runs serially after that. So there's all kinds of different things that we've kind of had to um we've had to help support. Rainforest used to have like the rainforest way, you know, of like this is how you should do testing, very prescriptive and it's good, but sometimes you got to meet your client. Not sometimes, you really got to meet your clients where they are, right? It's like, oh, we like you should have all of that stuff worked out and it should be, you know, a blocking step in your CI like if nothing passes or one test fail, you know, you shouldn't release anything. And then same thing, you come across clients who have are happily using the app with half of their tests failing on every single run. >> Wow. Okay. >> And they're happy that those tests are failing because they just expect those tests to fail, right? And maybe one day they'll get around to them, but they don't want to take them out >> because they like having them there. You know what I mean? Like there's something about their process that that makes them feel good that even those failing tests are still failing. Sometimes the failing test can be a little bit of a weird security blanket or >> yeah, >> who knows? Let's talk a little bit more about your stack there. So you mentioned so Rails using I think React on the front end. Is that across all of the front end or like in and any backend type tools as well? And then where does React code sit? Is it in the same repository or is that a separate repository that how does how are you kind of organizing that over there at this point in time at least? >> Yeah, React is is a fully separate repo. It used to be part of the main app, but it got split out before I joined and that was almost eight years ago. So, it's been a long time that it's been its own thing. It's gone through multiple [laughter] iterate in typical React fashion. There's all kinds of stuff going on in there. We have a front-end team that is specifically deals with that. Everybody's allowed to kind of mix and match, right? But, you know, they're the experts, so we let them do the React stuff. Yeah. And then on the back end, so everything you see except for the login page uh is is that React app and then that React app makes just your typical HTTP request to to the monolith. There's been a lot of discussion in the past about exposing things like V manager to the front end or V control to the front end, right? Or some of the other things. And we try to make sure that like everything ends up going through the back end like the main monolith for a number of reasons. Mainly because then you only have to off in one place. >> Sure, >> that's nice and easy. But there's also that like when you know that there's one place to go then the back end can capture that information and log it. You know there's one central place for all of that to happen. Are you exposing is it like everything then just through like a Rails API at that point then or do you have like any web interfaces that are built in Rails spec entirely like in the back end like >> uh the main Yeah. like so the main admin the admin for for the monolith is all is bootstrap too if you can believe it. We still got some coffees script in there too. >> Okay. Sure. Sure. >> Hamill templates uh just yeah it's it's been around for a long long time. The V manager interface is all Rails-based. And then we have a couple what are really microservices, which is like a an email inbox um and an SMS inbox because part of testing you're going to need to send emails. You want to make sure that you can get those emails and and respond to those emails. Same with SMS. So those are their own little things. I mean they are super light. Super light. They I'm not even sure if they have admins. If there are, there's almost nothing there. It's just like an excuse to get to the good job admin page, right? Like that kind of thing. >> So, are you using Good job primarily or using any other background? >> Oh, yeah. [laughter] We migrated almost everything over to Good job except for the main app. The main app is half Good job and half QC classic. I don't know if you know Qclassic, but it's a database back background job processor that was written at Rainforest and released um as part of open source. Um, we're trying to get away from that because nobody's like we're not maintaining it. Nobody's really maintaining it. So, it's just kind of laneow for a while. People might ask, well, why would you do that? And the answer is, well, because it's so old that there was no database backed background job. >> Yeah. Yeah. >> At that time, at least that's as far as I understand it, that was the the impetus for for creating it. So, so yeah, right now we've got about half of our jobs in one and half of our jobs in the other. And like it would be nice to fully migrate it all over to Good job. I mean I don't Was Good job a a good choice? I mean that was before Rails 8 with um I can't remember the >> solid Q. >> Yeah, solid Q. I'm looking at that and it's just well should we just bail on both of these and [laughter] move everything over to that like I don't know >> that's an interesting thing to consider there given that you're already already have them separately is I had not heard of QClassic before. I'm looking up right now on GitHub and is that integrate with active job? I think it does on a couple of the branches. This is the problem, right? Is that nobody and because we're not really >> supporting it as much. >> Yeah. Not supporting it. And it is QClassic itself is owned by QClassic, the QClassic Github or we have an extra thing called QClassic Plus, which wraps all QClassic stuff in a transaction and does a bunch of other things that we own. We just haven't reached out to anybody to try and do anything. So, every time we needed to do something, we would just create a new version and then point our gem file [laughter] at it. >> That makes sense. You know, you said you've been there for about eight years there or so now. In your opinion, what parts of the architecture have been the most stable over the years and what parts have been, let's say, more turbulent? >> Most stable has probably like uh it depends on what you mean by stable. We use grape for the API. Again, this is back when we had a lot more when we were a larger company. Earlier on, we had the notion that we would have a public API and a private API. And that was all with good intention. The CLI uses the public API to do the stuff that it does. You know, we did have some clients who were writing against that API. And then we discovered that the performance got worse as we got more data. So, we needed to slim down the responses. And we did that by using a slim param and then a slimmer param and like we just kind of kept going down that route all because we didn't want to break the public API and we didn't have a really good way of deprecating APIs like we our API I think is at like an API v1 or slash1 URL. So we can do it. It's just so much more work to kind of go down that route. We've never done it. So in that sense like the the public API has been pretty stable and >> stable. Yeah. >> Yeah. But the private APIs we've kind of moved away from and I don't know if this is for good or for ill but the more restful sense of picking the perfect resource name and putting your gets there and having filters and that kind of thing. Um mainly because we do have a lot of data and we've had performance issues. uh we still do have performance issues and so in some cases the front end has the ability to gather all of the data already, right? There's multiple endpoints for it. Just go and get it. And maybe that's how we do a first pass and get that up, but it's normally super slow because we're making multiple requests and those requests can take a while. So what we've started doing is making like very specific endpoints for exactly what it is that the uh that the front end needs and that's fully private. So we we can change it as much as we want and that seems to have worked out quite a bit better. Now it means an explosion of endpoints and because they're private we don't have docs for them [laughter] right. I'm sure we could I'm sure we can figure uh configure grape and uh uh swagger in order to get us those things, but there's a lot of like hey front end where are you guys getting this information from? And they tell us and oh okay you know you can grab that no problem. >> Out of curiosity for our audience approximately how large is your overall engineering team at the moment which across backend and say front end? >> Right now we're seven. Okay. >> There's Yeah, we've got two front-end engineers, three backend engineers, but that includes me. So, it's more like two and a half, two and a quarter, and then an ops engineer. >> I think that kind of helps illustrate a little bit into some of the challenges of a say a smaller I'm quoting smaller team. I don't know how big the team was approximately at its largest. Do you do you recall or >> So we've gone through multiple downsizings and when I got hired we were expanding and I want to say we were clo engineering was probably between 40 and 50. >> Okay, >> something like that. And then after the first downsizing we went down to 15 20ish people and then the last one we went down to this seven. So, it's been Yeah, there's a lot of code that a lot of people uh worked on. They're no longer around to explain uh just exactly what they were thinking. >> Yeah, thanks for sharing that. Uh, I think if we get time, I'm going to dig into that a little bit more. But I think that at least the context of knowing that like when you're working with your teams, like your front end's trying to gather some details and you're like, well, you're pitting all of our restful APIs is kind of like the default way that Rails developers would kind of think about exposing that historically and you're like, all right, you fetch some details and then you got to go fetch some other details based off the information you get. You're not maybe grabbing everything in one single request. I've talked to plenty of other companies even on this podcast with much larger engineering teams are like the conversations between the front end and backend air coding backend teams just doesn't happen as often. So they're like all right we'll just give you GraphQL so you can just >> you can tell us what you want and we'll give it to you. And I think if we hadn't had that conversation at least to talk about like how big of a team you have you're like well does GraphQL make sense at a team size of say less than 10 people or is that I'm assuming your team has maybe talked about it. Is that a safe assumption? Yeah, it it I mean it's one of those things that just perennially comes up. It was and I believe before I got hired, so I mean this was a long that was a long time ago. Somebody gave it a try, but I never really got the particulars of why that failed. Um and I think it's part of it might have been like the wrong just the wrong incentives, right? It was literally like so that we didn't have so that back end didn't have to talk to front end anymore >> versus like how do we actually maintain this and get it working and so the it is funny though because like we have all kinds of well I won't say failed but uh not entirely successful experiments still living in the code bases. So why that was the one that like got put up and then immediately got ripped out, I'm not I'm not exactly sure, but yeah, at this size, right, it it's it's one of those things like we're not big enough to be able to do it, but it seems like if we had it, >> maybe it would be better, but we're also small enough that we can have the conversations that need to be had, right? Like we work very closely. Everybody works closely. We're on like one large team. Everybody knows what everybody's working on. Everybody can help out in some way. Our product manager is like directly involved. Our designer is directly involved. The way that you would think of like uh I can't remember who it was that like that squad-based system of like we'll put everybody >> Yeah. >> in like the like a little thing and you'll have everybody gets a designer and everybody gets a product manager and that kind of thing and they'll all like do their own features. Well, we've got that but we only have one, right? And it it's really high performing at that level because we all know what we're doing, right? Nobody really steps on each other's toes and there's a lot of hey here's your endpoint. Does it have everything? No. Yeah. Okay. Well, what do you need? I need this and I need that. >> Perfect. And we just add it in. Right. That it's the iteration that that really gets us. >> That makes a lot of sense. You know, you mentioned there's been a lot of experiments. What are a couple of those experience if you don't mind mind me asking that you would have in retrospect would have wished hadn't survived or [laughter] >> I'm not even sure that it's it it's not so much that I wish they didn't survive it's that I wish they had like seen themselves all the way through more than anything right I'd like to think we still have a really good culture but back when we were a larger team we had like a really good culture of supporting those kind of things like if you want to try something new you know you read about something you want to give it a shot go ahead give it a shot But understand that like if this works, you're going to have to convince everybody else. >> Yeah. >> And it's not like we're going to run Rubocop and replace all the single quotes with double quotes because we all decided that that's the way that we want it to go. Like we're not going to be able to do that. So we're going to have these things and we're going to have to like put some processes in in order to make sure that everybody's using that. I mean, one of the ones that I brought in, which was the dry monads, um, which if people don't know, and they probably don't, I suggest checking out only because it's just it's there's something about it that suits my brain. Not the monad part, not the functional programming part, but the way that the code looks when you're done. that idea of having a set of like procedural steps in your typical kind of service object where you have find the user, validate the user account, send the user an email, log the event somewhere, doing all of those things. But knowing that if at any one of those points any of those things fail, it just fails all the way up to the point where you called it. Passing success and failure around is just really nice. and being able to compose those service objects together knowing that you're always going to be getting a success or a failure monad at the end of it. Like it's just it just looks really nice. I really really like it and we've used it in a couple places a couple important places to to be fair but it's just trying to just trying to get that as part of the policy and getting everybody on board with like oh we're creating a new endpoint. Don't just go and do the regular stuff, right? Like try and spend a little time and and use this because we think it's good in some way, right? Yeah. It wasn't really something that I wish had died. [laughter] It's it's quite the opposite. >> Interesting. Yeah. I've seen uh you know dry monads and that's was part of a dry RB, right? >> Yeah. >> Okay. Out of curiosity, is there a specific area of your application that you you find that that was really really helpful in implementing that pattern? Yeah, I was going through just to find like because I know what I did, right? So, it was I was trying to find some code that that um somebody who wasn't me actually used it on and we have the concept of like deprovisioning a client. We always soft deleted everything and then it got to the point where well there's two things. One is GDPR and that kind of thing where it's like clients want their stuff deleted so you have to delete it. Delete it. It's got to go out of the database. And then the other side was like our database is like over a terabyte. I think we're close to two terabytes now. Why do we have all of this >> data in here? Like we don't these clients have left. They're never coming back or if they do come back it's going to be completely useless. So how do we get rid of that? And so the deprovisioning process uses the dry modad pattern and just calls out each of those things because we have to when you delete all of the data for a client we haven't denormalized client ID throughout the codebase. So even though clients clearly own pretty much everything that's in the database some of them you can get directly to like an edge node of whatever that data is and in other cases you need to take two or three steps. So all of that foreign key consistencies, that kind of thing. You have to start at the edges, delete all of that stuff, come up a level, delete all of that stuff, come up a level, delete all that. And if any of those things fail, we need to know about it. You need to know where it was. And I mean, yeah, you can wrap it in a transaction, but sometimes there are outside things happening, right? Um S3 objects, that kind of thing. So there's a certain amount of like making sure that it all happens in a specific order and if anything goes wrong that it comes back up and fails. And so I was really it was really nice to like find that. I didn't realize that. I didn't I didn't have a lot to do with that code. So going in and seeing that it's like oh that's a really good use for it. And then the the other thing is because you can decompose each of those things down. can take the like, you know, delete all of the client's jobs and just put it in a different place and call it. And then if you need a job that like, well, we're going to leave all the client data around for this type of client, but they want to delete all of their jobs or tests or whatever, then we can just call that and know that you're going to get that success or failure back. >> I'll definitely include some links for our listeners in the show notes for you can go look up dry monads if you're not familiar. Are there any particular uh educational resources you remember coming across that were really helpful outside of just linking over to drb.org? >> Ah, that's a good question. Um, I probably got turned on to it from the the Rails email. What's the the newsletter that like everybody subscribed to? >> There's a few of them. Uh, the Speaking Rails or Ruby Weekly. >> Yeah, Ruby Weekly. And I mean I honestly just read anything that Evil Martians writes. Like I'm not going to use all of their stuff, right? I'm not going to go all the way down, but they have such a different way of thinking about code, just code in general, how apps are built and that kind of thing that like I always find something in there where especially if you're dissatisfied with some of the like that this is how everybody does it and you're looking at it and you go like but why? [laughter] Right? Evil Martians probably looked at that and came up with another idea. >> I'll definitely include links over to their blog as well. good articles on their end to our friends over at Evil Martians. Something I hadn't thought about talking about with you, but when you mentioned like the deeprovisioning and just having all this extra data living around your database or in your S3 buckets and trying to come up with a cohesive way to maintain that. Do you have, you know, you mentioned the GDRP or is that how you is it JD? >> Yeah, I can't remember which one it is backwards. We're from North America and so we're we're just subjected to having to kind of understand enough about it, but we're not we're not living and breathing in it maybe as much as maybe our friends in Europe are. trying to think about that. I know a lot of client projects that we work on where they just never get around to dealing with that stuff unless it's like forced on them because of something like a policy. But I'm like your your database backups, everything is just so much slower to do. Making updates with your migrations, updating some data, this takes so much longer because you have so much more data in your database. Why are you not deleting more of this stuff more often? And I think we've always be like, "Wow, it's just server space is >> yeah, it's free, >> relatively cheap, but [laughter] >> let's throw more money at it, >> right?" But there's also a lot of scenarios where, like, as you mentioned, you have clients that are no longer there, customers that are no longer using if they were to log in today and it's been seven years since they last activated their account. I'm assuming that most of everything in their system's not going to be workable in the way, you know? So, it's like what's it's an interesting like onboarding, deboarding, and then like a reboarding process. knowing that like you don't expect everything to sit around in this some database forever. So, you know, what's what's your workflow like? >> Yeah, just to carry on with that like we've had multiple discussions around that and some of it to do with just the the size and like why are we doing this, right? But like yeah, like what does it mean for a client to come back even after three months and look at a result of a test that failed three months ago, right? Like what what does that actually mean? Like especially if they're like working on their app, right? like he the the problem that we have is that well it's not really a problem. It's funny but this is my uh former boss and I used to talk about this all the time. Like do we have a data retention policy? No, we don't. It's like no you do. If you don't have a data retention policy then your data retention policy is to retain all data forever because you haven't set any other policy. So that's where we were. We had a data retention policy of forever. Now you can change that. You can change that. Send it out to clients. let them know, but you have to decide to do it. And then once you decide to do it and communicate it and do all of that kind of thing, then you can start enforcing it. But you can't just decide that we're only going to hold stuff for 90 days, right? Or 30 days or even a week, right? In some some cases, we have clients who create so much who are running so much and have so much information that even and are producing changes to their app so much that last week's set of test executions don't mean anything. It's nice to see historically that this thing was passing and then it failed, but eventually, you know, the there just becomes too much data there. So, but on the flip side, we do have clients who like they schedule a test like a run every month. And so, if you want they want their historical data, those people don't. The other people don't. So, like how do you make those kind of decisions? So, we basically got to the point where it's like the retention policy now is uh when you leave as a client, we can do anything to your data within like 90 days, I think, is the is the actual number, right? So we did actually make that decision and then we spent a really really really long time figuring out how to delete all of that data correctly and like when we did start deprovisioning clients like you know background jobs that were running for two weeks you know deleting all of the >> all all of the objects in because we don't tag S3 objects with any kind of client information so we had to get all the keys out of the database and go and find them and delete them individually, right? That kind of thing. So, yeah, lots of decisions that were made in the past because we didn't think about deleting stuff, right? And we had everything soft deleted. So, everything was just still in the database anyways. Works out some cases, but yeah, in other cases, you're just like, what? We got to get rid of this. Like, how how do we do it? And the answer is you take a long time and and and then delete it all. >> Are you doing any sort of multi-tenant in your app? >> No. We've another thing that we've talked about a bunch of times and it's always come down to [sighs] let's just pay more money [laughter] just get a bigger database in instance. >> Yeah. But we we really did kind of want that because that idea of like a database for your client. >> All right. And then like when the client goes away, you just delete the database and it all goes away. That's so nice. >> Yeah, it does sound magical. And there there's our S3 bucket. Bye. Um I understand it's not not as easy as it sounds. So you had mentioned that some some of you had more microservices in the past and you you brought some of them back into the monoliths. Can you talk about a few of those and do you remember what the original motivation was behind that and like what motivated you to Okay, let's backtrack that. >> Yeah, like the main one that comes to mind is what we call our integrations service. We have basically a place in the app where you can set up things like Slack messages, Jira messages, what else? We used to have, I think, if you can believe this, Facebook >> messages. I still don't know why. So, that was a a separate app. It got brought into the main app just before as I was being hired kind of thing. And the idea there was like we were touching a lot of things that needed information, right? Like the the microser needed most of its information from the main app. And it was just like this is becoming too much of a pain because every time we want to release something you got to release the changes for the main app and it but it's still not useful until you release the changes on the integration side and that kind of thing. So we took integrations and based on what I can see we just dropped it into the main app and called it done and exposed not well I guess there are really no endpoints. it was okay well here's all your stuff use it and let's just say it was written with a different philosophy [laughter] then like a lot of abstractions um a lot of trying to figure out what exactly is happening here tracing things down through multiple classes so on the one hand it made it easier to just do anything with the integrations because you could just make the change and ship it and then on the other hand it kind of made it worse because none of that was walled off or none of it is walled off from the main app anymore and it's one of those like It seems like such a simple thing, but it's like the scary place to go. It's where developers go to like not die, but like go to just waste time and it's everybody who gets onboarded at some point is asked to do something with integrations and it's just like but just so you're aware, you're going to be in there for a while. It's going to take you a bit to kind of figure it out. >> Do you think there was anything around that? when your team was a lot larger, the idea was like, let's allow these folks to just kind of work in isolate things a little bit more because the assumption was the team was going to keep potentially growing. And that led to a lot of that. And then you weren't really projecting, well, okay, if we're making decisions like this where we're going to break apart this, move the integrations to their own or just set up this whole thing in a new micros service, what have you. They're not thinking like, what if we're less than 10 people in at some point in eight years from now? >> Yeah. Nobody thinks that way, right? No. [laughter] which it is understandable. Um, but I honestly think that like based on the timing of it and when that integration service was written that it was peak microservices and so we needed the email inbox thing. So that was its own thing. SMS is going to be over there. V manager we have argued back and forth about whether it would make sense to bring it in. Probably not. But like at some point, you know, there was talk about it. So I think that that like oh it's an integration thing. it's going to be talking to, I don't know, name whatever services that you're going to be sending this information to. So, it should just be separate as well. And then the hilarious part is that once we brought it in, half of those services shut down. So, now we have all of this abstraction >> that written for another service assuming that it was going to be in like the the typical Rails kind of MVC kind of thing. So, it's got all of its own modelish things and you're looking at it's like there's only two. [laughter] Like, why is there all of this indirection in order to support like Jira and Slack? It's like, well, because we thought we were going to support more and then we just never did, right? >> That's a difficult balance that teams find themselves in. I think that's it's normal. Uh yeah, you assume you're going to keep growing if if or that your integration is going to keep increasing and like but then the reality maybe goes a different way. And I think that's being adaptable. Do you think that because you're working with Rails that's made those types of decisions less painful or do you think it would have been just as complicated regardless of the tech stack? >> Maybe not Rails, but certainly Ruby, right? Like just the gem ecosystem in Ruby makes it so easy to know that you're going to be able to for the most part I mean maybe it's a little worse now, but like especially back in the heyday that like there was going to be a Ruby library for whatever it was that you needed, right? So having it there, having it immediately at hand within the main app just kind of makes sense, right? Rather than putting it off somewhere and walling it off. But like it's similar to I can't remember what I was talking about earlier, but the idea that like the codebase has been around for long enough that stuff that most people would reach out like reach for right now didn't exist, but we've already got that thing baked in there, right? And like we've had to go through, you know, when they changed the Slack API, we had to go and change we had two different Slacks. We had like sending Slack messages, but then we also had like a Slack app. Well, then they got rid of the Slack app completely. So, we had to come up with a new way and it's always like we're always just kind of scrambling for things and it's but at least in that case it's in the context of stuff that we know rather than just kind of being off like in that Erlang service. It just kind of happens to as far as I know it never goes down, [laughter] right? We never have any issues with it. So, thank God it's just still doing its thing. >> That's good when things can just be reliable like that. I'm I'm curious about your team's I don't know if it's changed over the years, but what's your current philosophy or ethos on when do you bring in a community say library or like gem into your project? What sort of signals are you looking for like this might be a good tool to lean on versus like we'll just in build our own client library for some third party API or whatever the particular scenario is. Do you have a a kind of way of how you think about that at this point that might have changed from how it was a decade ago? >> Yeah, I mean when I first started eight years ago, I think there was just there was enough like engineering teams because we had so many engineers that, you know, we're giving people features, that kind of stuff. And so there wasn't really a top- down this is how we should think of these kind of things. And so everybody was kind of like left to their own devices. And it's that typical thing where it's like, well, there's a library for it, so use the client library, right? and then call that client library every place you need it. Then that goes all the way through there. You know, no writing of adapters, no anything like that because everybody thinks that you know what are you going to change your database, right? And then you do, not us, but like we just had a thing where all of our internal metrics that we uh kept track of, we were using Labrado for um Labrad got sold to Solar Winds about I don't know six or seven years ago or something like that and we were still grandfathered on the old Labrad. And then they just sent us a thing. It says, "Yeah, Labrad is going away in September." It's like, "Okay, cool." But like we use that for all of our event data. So across all of our apps. So we didn't have any adapters. We didn't have anything to go like, oh well we'll just send this to data dog instead, right? Instead of pushing it here, we push it there. It's like you have to find every call the labrad in across all of your apps and like you know it was a good exercise for us like just removing some stuff getting rid of a bunch of that stuff. That's the kind of thing that I think in terms of like you don't think about what it's going to be like when your when your team is much smaller. But even in that sense like it maybe it's not your organization is smaller but your task now with like you've been put on the there was no teams before but now you're put on the platform team or the integrations team or whatever and when you're that small there is a tendency to like like you can oh we all agree right all five of us agree what about the other 50 people who cares right so trying to keep that communication open and going and then you know it's just a typical trust as well Right. At some point, you need to just kind of let the devs do what they not what they want to do, but sometimes they do. You know, you do kind of need to learn from your own past uh I won't say mistakes, but just decisions. This episode of On Rails is brought to you by skip forgery protection because who needs trust tokens when you've got trust issues. Are you building a quick demo or a halfbaked prototype or something you promise you promise >> no one will ever use this in production? Then you, my friend, are ready to skip forgery protection. Why verify request authenticity when you can just believe in the goodness of the internet. With one line in your controller, you can bypass Rails' default safety net and invite strangers to post whatever they want straight into your app. What could possibly go wrong? Skip forgery protection, like taking the batteries out of your smoke detector because it was beeping a little too much at night. Fast, questionable, beautifully reckless. You mentioned like that example of uh maybe not initially integrating with an adapter layer between you and whatever thirdparty service. Is that something you would encourage developers to think about doing from the get-go? Now, how do you make that say third party gem? An easy one that I always bring up when I have conversations with developers like all right, it's really great that Stripe made it so easy to integrate with their platform for applications. Yet, we have a lot of clients that come to us and they're like, "Hey, we want to add PayPal because not everybody has a credit card and around the world and we want we want we want people to pay us for our product, right?" And so, they're like, "Well, your database has a bunch of columns called Stripe ID and your codebase is just littered with Stripe code, like literally from their gems, you know, that I'm like, which made it great, but we're kind of a little in a weird pickle here where like let's not just like add another thing on and it's easily just going to be a quick thing." like this is a kind of a complicated problem and so maybe I don't know what the answer to that all the time is and people say well Stripe has some PayPal integration it's not the same not everybody's looking for it but I'm just curious of like do you think about that a little bit more when you're going to reach for a gem and be like okay well we're going to lean on this but I'm going to also take a little bit of extra time to do something in between me and that gem >> yeah this is like my hobby horse right now [laughter] simply because of the lab stuff we are in a similar situation with uh not Stripe necessarily needing to support PayPal, but more like we need a different set of pricing like we need a different pricing model right now and there's a lot of stuff that is just baked into the current codebase right that will not support that model. Um but we had you know our um client metrics or you know keeping track of like when users click on things and where they are in the app. We had we were using amplitude we turned off of amplitude and went to mix panel. all of that stuff was being sent through segment and it's like well segment was supposed to manage all of that but we didn't do a good job of that. So yeah, to your point, it's like this is the thing that I think regardless of how big or small you think your organization is going to be in the future, it really really especially for thirdparty services, like it really makes a just sense to even if it's just a super light wrapper around whatever it is that the uh that third party call is going to do, right? Even if it's just sending event data, right? because you never know what the next library is going to expect from you. And having to go and update every single call point, right, every single place that you're sending events to, right, is crazy. Now, with Ruby, you can fake it out by basically getting rid of the gem and then having, you know, you can monkey patch your way to uh great success, I guess. Yeah, I wouldn't recommend it. So even just having like light rappers and then also please please when you write the rapper name it for the generic thing that it's doing like right now I swear I just saw we have an adapter around stripe calls that is namespace stripe. It's like, well, okay, [laughter] so if we like that's not great. Like that should be like payment processor or something along those lines, right? Just to make it very clear that like this is the thing that it's doing. And eventually we're going to get around to sending stuff to Stripe. But the rest of it is like you really need to think through those decisions and be very precise about what I mean it's the naming problem but at the same time if you get it right or get it close it saves you a lot of trouble down the line because I would hope that your organization is so successful that it becomes so big that you need to support multiple payment processors or that you just outlive yeah >> right all of those services right that's a good problem to have but from my experience you do not you do not want to be under the gun having to change things out because especially when a service is shutting down, they might be good to you or they might not. You may just find out one day that they're done and now all of your code is just useless, right? >> You know, for our listeners, I think this an interesting thing for people to think about anything that you're you're giving money to to keep your platform moving and integrating with other, you know, other services. It's something that I thought about as you as you were talking here. I was like, why are we not may maybe something that people do is like, is there anyone out there that's like adding rules like linting rules to like if any of these vendor names show up in anywhere outside of like a gem that's being called in like one, you know, wrapper like flag that like someone's touching something in the wrong place in the application like that could be an interesting I'd be curious if anyone out there listening is doing anything like that just to help remind those other 50 developers on your team like be cautious like this is the pattern we're trying to follow. Let's be very mindful not to have if you know sending something specifically to data dog from a controller, we should probably passing that through some wrapper or something and then sending it to data dog. But at the same time, the incentives for all of those platforms is to have you be very very coupled into their system. So their code examples you're going to find on their API docs, their developer guides, >> it's not going to necessarily be advantageous to you being able to switch away from them one day, >> especially when you're wrapping things in blocks in order to, you know, capture data from a span for data dog and like yeah, it's hard to be that generic, right? But in some cases it's like at the very least you know the I got through this labrad thing and on the other side of it we just have a we just have a metrics namespace that calls like what I don't know like send event or you know those kind of things so that at least we have that right so if we do need to swap out data dog with something else [laughter] which is who knows right like and the other thing too is just reminding people that like this isn't necessarily just about whether you think the company is going to last right this third party vendor or whatever This is business, right? And business things go sideways a lot of the time. They decide to raise their price. You can't afford it. You have to churn, right? You want to churn. You don't like you just don't like what they're doing. There's all kinds of reasons that you might not need to come off of that. And so, if you do it upfront, then it just makes that decision so much easier as well, right? It's like, "Oh, well, yeah." No, because the last thing you want is to tell a manager that it's going to take, you know, a month of engineering time to make this change over to, you know, a vendor. Then they just do the math in their head and go, "Well, that's how much you make in a month. How many developers and then how much was extra was I paying? I guess we'll just keep it." >> Yeah. >> Right. Like, I mean, that's math. That's business, but it's it's not satisfying. >> No, it's not. And you know I was having a conversation recently with uh Kemp Beck and he's talking about optionality and something come from his one of his new books that he came out I think maybe last year for whatever reason then the name is oh tidy first is the name of that book but uh he was talking about optionality being a thing that developers should be thinking about like how are we building things and how are we keeping our options open in the future but not necessarily at the cost of still making progress. I think there's that balance like you could like make things like over generic like premature optimization you know to for like this will allow us to do anything in the future but also knowing that like you can fast forward down and like yeah platforms evolve and change or raise prices or get bought by VC and then that you don't like coup or private equity and then the company changes and you find yourself working you know Solar Winds owning something that you're still integrating with years later and they haven't made any feature updates to the platform the application that you're still paying for. it's not going to get any better for you. And so you're like, well, what do we do? But the cost to change to something else is way more than the couple hundred dollars a month you're going to save. So you're not going to do it. But the developer experience and the maintainable experience for your Rails application might not be as pleasant as a result of that. And so how do you make those switches cheaper in the future? Not necessarily. They're not going to cost nothing. >> Yeah. Minimize them as much as possible and and realize that like even if you have a dedicated platform team, they probably have something better to do. But when you're especially as small as we are, like I took that on simply because the other developers have real stuff to do, right? Quote unquote, like real product thing. We're trying to make our product better and trying to figure out how to switch from one metrics platform to another doesn't make anything better. >> The adapter thing is just that's just one of those where like it feels like abstraction. It feels like, you know, early optimization or whatever. It's just like no, no, trust me. this is this is the one place where where you definitely want to do this. Um you won't regret it >> and it's just easier. It's like it's nice to gp for it too, right? Like you can just find every place and like okay throwing that like yeah GP for stripe in your code and hope that like you know one line comes back where it's instantiating the API client. >> Even using that one example stripe it's like a lot of those gems will then install or create database columns and then there's there's there's a little bit more complexity than just maybe wrapping the gem itself. But I do think that it's worth exploring that a little bit more. And my my fantasy world would be a lot of these vendors would actually encourage you to do that. And that would be actually a value ad, I think, for developers be like, "Hey, look, >> we're making it so it seems a lot more relatively simple to switch away from us, but you don't need to because we're we're the one that's giving you all the great stuff anyways." Not that I think that's like they have any alter that I don't think it is the the reason they why they do it that way. I think they're just trying to make it as simple as possible to integrate with your platform. But out of curiosity, do you think Rainforest does enough to you know if you're going to integrate with Rainforest is that it's probably like all your documentation is like this is how you do thing with with Rainforest, right? So it's not like here's how you could take the same and go to one of our competitors and do the same thing over here. It's just kind of how that works. It's kind of on the developers to figure that stuff out. >> Yeah. I would argue that you can't do what you do with Rainforest with anybody else. [laughter] >> Tell me more. >> I'm sure business will be happy to hear me say that. Give give me two examples, Jay. Come on. I'll put you on the spot. >> Oh, okay. So, right now, our big push is being able to generate tests from scratch using an AI, using a prompt, right? And there's a lot of companies out there that can do that. But what we provide you at the end result is a rainforest test that is then executed by rainforest the same way that if you had gone in handcreated the test. We don't use AI to do the execution. It's not always using the prompt in order to drive your test out. Maybe some people don't like that, but that means that like if we generate the test and it's not up to your speed, not up to what you actually need to test, all of that kind of thing, you can go in and fix it and then execute it and then it's done. I mean, that to me that's like that's our big selling point. And then the other one is because we use we can argue about whether you should be you know um trying to find things via the DOM or via the actual image that you see on the screen but we have found that like that's how people think about stuff especially just that like above the developer spot and not having to know what the actual DOM ids are and all that kind of thing. It just makes it easier just like well what do you want to click on? I want to click on the login button. We'll draw a box around the login button. We take a screenshot and then we find that login button. But the thing is we're going to find that login button no matter where it is on the screen. >> So you can move your UX around, you know, within reason, that kind of thing. It's still computers and [laughter] there's still we, you know, there's still some things that we can't do. But that that's the other big one is having tests that still execute but have a little bit more leeway when you're actually trying to like go through the app. you can move things around and not have to necessarily worry that like well it's not at that or like the same with coordinates anything could be at those coordinates it's the web right >> sure that makes sense safest assume I think you already kind of alluded to this that you test your own dog food and yep >> as part of your own testing workflow uh outside of using rainforest QA to test the you know maybe the front-end part of it what's your testing framework and stack look like there what's your strategy >> for the main Rails app and for basically all of our Rails stuff it's RSpec at the lowest level our admin which I said was in the which like you know has uh uh HAML templates and all of that kind of stuff. We actually still have like view tests >> like testing the actual views the generated views and it is just a nightmare to make any changes in the admin. So we're moving those over to system tests so that we can do at least basic are the things in the admin where they're like on the page where they're supposed to be and then that's pretty much it, right? Then we put Rainforest right at the very top of the testing pyramid. So we have I can't remember maybe 12 10,000 tests something like 10,000 specs and then we've got I think around 200 220 rainforest tests that all go out. The nice thing is we run those same tests against the the front end suite uh when it goes out. So we're always checking whatever goes out. Yeah. Whether we've broken anything at at any level. It's certainly saved us a number of times. >> You know, in preparing for this conversation, you'd mentioned that you prefer air quoting wet tests. Could you tell us a little bit about that? >> Yeah, if people aren't familiar, the the concept of like drying up your test to the point where, you know, you're using the subject and and lets and um the like nameless or example list it blocks. So, by the time you get down to the actual thing that got executed, it's like I don't even know, you can't read it, right? like and it's always bugged me just from a I don't know what's happening standpoint but if you've ever had to deal with those I I had a contract with a company where that was standard and they would not accept a PR that wasn't written in that way. So what you ended up with was I don't know like a two or 3,000line file. You're down at like line 2500. your six contexts in the subject is changed three times. The lets right the the like in our case it would be like you know just a client object or whatever but that client has been modified or changed or overwritten or whatever it is uh so many times and then there's also like a lot of people don't realize that like subject is memoized so if it's been called and then you call it again you're not re-executing it. there's just so many so many things that go wrong and then at the very end of the day you just you can't tell what is happening in that test and so when it breaks it's just impossible to fix and so I've always been kind of a fan of like whatever collaborators whatever anything needs this is kind of test driven in a way right you're forced to enumerate all of the things that you need in the test what's supposed to happen is you go this sucks there's just so many things here >> and then you figure out a way to fix it, not by necessarily fixing the test, but by fixing the code that it's calling, right? And then there's the other thing too where it's like in certain cases, you're going to have to create objects a specific way inside of this test file. You don't need to use lets or anything like that. Just write yourself a nice little It's still Ruby inside of there. to write yourself a method with a well-n named name that says like what this thing is creating because the other thing I find is like they use generic names right all the way down. So it start the very top has a client and then every thing that changes as you get further down into the context it just says client again. So you don't know what that client is. How is it changed? What is it? As opposed to if I was just writing it inside of a regular example and I've got like um unsubscribed client, it would be the name of my variable, right? But you can't use unsubscribed client in that test because client is relied on by whatever two other things that are being created, especially clients, right? Because they're like the god. Everything belongs to the client. So what ends up happening and this is I'm really on the soap box now but what ends up happening is you become the llinter compiler you have to hold the entire stack >> right >> of whatever is happening inside of that test inside your head and god forbid another example didn't didn't fail you know a 100 lines up right so and everything that you're looking to see is so far away from where you're actually working I'm looking at a test down here but the client is declared at the top of the test and the thing that the client or that belongs to the client is halfway between those two because the context is switching around. Part of it is like it's not readable, but it's also not understandable. It just slows everything down >> cognitively in particular. >> Yeah, >> there's a uh I think if I recall, I think THBOT has a good blog post on this if I recall. I'll include a link to that in the show notes for folk on wet test and um I had one of their developers on my other podcast I think earlier this year. We talked about this a little bit more in depth as well. I'm curious, uh, what are your thoughts on do you lean heavily on things like factorybot or anything? >> Yes. I [laughter] mean, yes, for good and and for ill, I guess, to some degree, right? I try not to reach for factories. Like, we have them. They're available. They're there. We're using them all over the place. It's one of the reasons why I think everything's so slow. Um, mainly because factorybot hides all of your associations. And then when you do get the like the worst thing is trying to you create something down at the bottom of the tree. The job group needs a run. The run has run tests. the run needs a client and you just so you end up creating 15 things but all you needed was the thing in this one specific state normally state right like I needed whatever I needed to have have passed from one state to the other and like but you get all of this stuff up at that higher level which in a lot of cases I mean it's not that it makes sense but when you look at the code it makes sense because we are those things are doing database stuff right they're they're making changes in the background and we're checking we're reloading ing objects and or models and checking to see what happened. Um, but I prefer not to write that way if if at all possible. But Rails makes it hard, but it's more that Factorybot makes it easy to to just get the thing that you need in the state that you need. But you really do kind of forget that like there's a lot of stuff coming along with it. And we also a long time ago used Factory Bot to generate our seeds. So yeah, you can see where that goes where it's like, oh, we just need, you know, we need to seed the database with this test and it's like and we passed a whatever a client in but so the client and the test are set up but we didn't pass in all of the other associations. So all of those got set up but they rely on the client and in some cases we weren't doing a good job of making sure that that client was getting passed down. So you're creating things that belong to a test but that belong to another client. It was it was a mess. We since cleaned up a lot of that that but that was again a huge huge project that we had somebody take on when we were bigger. I'm curious about given your domain, hearing you talk about your clients, customers, they're running their tests. Does that level of the the just the vocabulary is that an interesting challenge unique to your you feel like there's a unique thing about working in the space of managing a platform for running tests and also writing tests in there? And like is there an interesting like when you're having conversations like are we talking about our clients tests? Are we talking about our own tests? is like is there weird overlaps there that you're like this is kind of I'll just leave that as open question I think >> I mean the one thing that I think anybody who has ever worked for Rainforest would agree on is that we are we internally are horrible at naming things whether it's projects or things and some of it is for good reasons some of it is for really bad your typical just like oh that was a funny name and then it's stuck and now nobody knows why it's called that and it's embarrassing to even just say it out loud kind of thing but we have a hard time because I think when it was initially spun up the original app, they wanted to use test for the model, right? We have test, you're creating tests, you're writing tests. It stepped on like the test unit framework or something like that. And I'm sure that there was a way around it, but there was some kind of conflict. So they just went, "Oh, we'll just call it RF test." So now we have a model named RF test that we all refer to as tests but we have a lot of associations and in some cases the model refers to the RF test ID or we called it test ID and we did the Rails dance to make sure like all of that kind of stuff. So like even within the app we don't know what a like you know what a test is but it's yeah having to have that conversation outside of it right making clear that like most of the times we'll talk about rainforest tests which are the tests that get written in rainforest but then we get into you know interesting side stuff that might be too much but like when you create a run we snapshot your whatever tests are going to run we take a copy of that so that while we're in the process of running if you make changes to the test, we are going to test the thing that you ran, not the changes in the middle of making. So we call those run tests. Those run tests have steps, right? Each of the things you're going to do is a step. You can embed tests in tests. We have a join table called test elements that. So it's just it there's all of this kind and then down at like the actual execution level, we refer to the thing that gets there's like the overall run, but your test that gets executed is a job. And there is like the base class, but we have job tests, right? And then we have like automation job test, right? So the original job test is for the tester community kind of thing. We've just overloaded so much um information. It's like yeah, it you know the joke about naming being one of the hardest things. It's like yeah, it it really is. And when you get it wrong, it makes it a lot harder to just talk through stuff. >> I bet. Yeah. I think if you're I always look like if you have to have some sort of glossery to explain like okay but what thing are we talking about? Are we talking about our own thing? Are we talking about this thing? Uh there's a number of uh projects we worked on over the years and like it's it'll just be like their their business is like they have applicants or applications and you're like an application form you fill out and they're like and then they try to name it like that and you're like okay well we got all this application application controller and you got some weird controller with also with the word application in it and people get confused when you're doing a quick search in your your code editor or something like that and it's the fun part of our job, right? >> Yeah, exactly. we have like a folder which is like a a thing that you can put tests in and at one point we decided that that was actually called a feature. >> So the idea is like it tests your apps feature. So from the user perspective you're not creating folders of test you're creating you're naming your feature and then you're going to put the test that tests that feature in there. But on the back end we don't have anything called feature. We have feature flags but we don't have features. So if you don't know what it is like you're just like what is going on over there? But yeah, you need to know that like the endpoint is named folder. I think uh you know what it may be called feature but we return a folder object like [laughter] it's you know like you just get into that thing of like being careful like what are you naming this having a like a tight-knit group that is deciding on the new things that you're building and coming up with that stuff ahead of time because we don't want product talking about something that that is getting translated to the front end that is getting translated again to the back end because we came up with the name but you know front and named it something different in >> uh in the React app and then product goes oh that name's not flying so they call it something else like we can still we got database like we've already written all of this stuff right like it's we're writing to databases stuff we're not making those changes so you just kind of suck it up and put a comment up at the top of the thing [laughter] and hopefully that's enough >> the joys of the the decisions that we've made in the past and the decisions we'll continue making and we have to live with them. >> Yeah. You mentioned earlier that you have a pretty large database and is it safe to assume you've had some performance challenges like reporting or anything like that and like how do you think about gathering data about that volume about your customers like if you need to build out any analytics type tooling for your admins or for your customers how do you approach that there building that stuff out it's funny because we've been we moved off of Heroku onto Google cloud I don't know about maybe six or seven years ago seven years ago And with that comes a whole bunch of stuff that Google provides that you just don't think about until you think about it. And back then we were large enough that we had what we called the science team. And the science team was doing things like coming up with our machine learning model for doing the image matching that we do. And then just doing interesting things with our internal client data, you know, how much they run, what they're running, all of that kind of stuff. And so they put all that into BigQuery. BigQuery is like the place where all of our analytics kind of like start. Yeah. Anything that's happening in the app, we don't write immediately. We do like a daily or twice daily sync to Big Query. Everything gets shoved in there and then we've got a couple ways of getting that information out. We used to use it mainly for like internal stuff, right? Board meeting. They want to know X amount how many how many tests have been executed for the last 60 90 or 30 60 90 days, those kind of thing. Trending charts, all of that kind of stuff. So we would write the queries against BigQuery. BigQuery is cool. It's one of those things you got to wrap your head around because it doesn't work the way that the way that you think it does. We have since I can't remember when we did this, but we launched Redash, which we're hosting ourselves. And Redash is essentially like a front end like a SQL front end, right? Write a bunch of queries and you can save those queries and you can visualize those queries like nice simple kind of thing. We use that to answer those same questions. Now we don't have to do quite as much stuff in BigQuery like and by in BigQuery I mean like we were using DBT in order to capture some of the SQL and stuff that we were doing. But for Redash it's just really nice. You can point it at BigQuery but we've also got it pointed at a readonly version of our database. So if you don't have whatever post to code or like actual CLI access to the database, you can hit the readonly database and like ask it whatever queries you can you can think of. And so our customer service managers are using that whenever we have board stuff, we can just somebody can write a query, save it in there, and hand it off to whoever needs that information. You can set it up to refresh or it'll just like cache that information and whenever you want a new version of it, you just go and reload the page and get it all again. So, it's pretty cool. >> Have you intentionally like removed a feature that was built just like say within Rails and just kind of entirely moved it over into relying on BigQuery? >> Uh, no, we didn't remove it. We we just recently launched a new basically internal client metrics, right? clients wanted to know all of their stuff, how many tests have failed and how many executed, creations, all that kind of stuff. The typical thing that you would see on like a on a decent dashboard and um we were looking at doing that, but we we came across a project called Cube.js. And CubeJS, it's basically like how do you get your front end to talk to BigQuery? Because BigQuery has all your data, right? And so you can't just have you can't just be making requests, right? Even if you've like got that worked out, you don't want to have all client data exposed kind of at that API level, right? We need to have given the current client who is logged in, what do they have access to? And so Cube.js gives you uh basically a way of proxying that off, which is really nice. Cube.js has its own thing. It sends a client ID. We send it to the Cube.js JS instance and then you declare basically just a set of um essentially views into the BigQuery database that will let you do filtering and grouping and that kind of thing. But it's all based on what is actually sitting in BigQuery. So the the like the meat of it is we have BigQuery views for that. And then Cube.js JS just kind of sits in front of that and lets you access only what you need from it at the client level and then lets them change dates and periods of time and grouping and that kind of thing which is pretty nice. >> And that's primarily as like a readonly >> Yep. >> type of thing. So, I'm just thinking like earlier we talked a little bit about GraphQL and for anyone like looking at different options. Is this kind of like an alternative path if you're just using this for a like a read only like be able to display information to your users instead of maybe going down the path of maybe integrating GraphQL if you're only primarily doing that for displaying. I'm guessing maybe those with the GraphQL are probably need to do a lot more writes as well. But is there some overlap into the functionality that these patterns are offering? Yeah, I mean I don't know GraphQL that well, but I do know I do know trying to get a Postgress database to just compile a bunch of stuff when you have like millions of records in a table that need to be joined with another million records, right? You can kind of think of like the Cube.js, the BigQuery thing is like that's where your cache is, right? We don't provide you and it's very clear in in the front end that you're not getting real-time data. You're not going to kick off a run, see it complete, and see those those tests show up in that. You're getting it once or twice a day, and then that's it. But that allows us to offload all of that to those services, which are good at it, right? Versus the well, I want a count of all my tests. All right, we'll go get a count of all the tests. I want a count of all the failed. And and as soon as you start compiling all of this data, especially at when I say scale here, at the scale that we're at, I don't mean like the amount of clients that we have, but we just do have a lot of data. So when you start slicing and dicing that, the performance is just horrible. Um, so we've done some internal caching and that kind of stuff, right? get to the end of a even just like trying to count. It's never the like what how many tests were executed for this run. It's like you're on a page and you're seeing all of the past runs and it's in a table and there's a count of all of the tests that were executed in those runs. Well, now you need the count for every single one of those runs, right? and they page over and they go get and then they page back and so there's like a little bit of caching there but you don't want to be counting all of that and then just keep now now keep splitting that right it's not just tests it's passes and failures it's this and that so you're you're constantly trying to figure out what to do there and like we've solved that in a couple of ways that are they definitely got solved right um but it's not ideal and so we just saw that as like well we're going to put all of these graphs on the very first page that you log to and we're just gonna every time somebody logs in, we're just going to make all of those queries. We already know it's like not tenable, let alone trying to group them by date and that kind of thing. So, it's like what can we do? Well, we have big query and right that's where all the data lives. So, this seemed like the if you can believe it, having two separate services provide this data is way easier than trying to get the performance out of the Postgress database that we normally would. You know, I talk about that with a couple other guests, I think, where there's that challenge of like you sometimes displaying metrics and data that but let's say like a dashboard page where someone logs into your interface because like for whatever reason the product team thought that would be the interesting information people want to see first, but yep, >> sometimes that's a really expensive hit just to load that information and they might be trying to go down and do a different task that just happens to be the first page that you're landing them on. And so you're hitting your database a bunch depending on the size of that client and how much data they have and there could be pretty big hit. And then teams are then trying to optimize that page because it's so frequently hit. Subtext here also maybe maybe not actually what people are actually wanting to look at. It just ends up being the thing you display at them. So what can you do to speed that up? And so people go down the path of trying to cache things and trying to optimize behind the scenes and like this could be another alternative like what if we just speed up. Maybe another question is like maybe you don't land them on a dashboard of a bunch of graphs that they were actually weren't looking for yet until they click there. But that's a product decision and I'm just going to get off my soap box there for a second. But >> yeah, exactly. [laughter] Jay, I want to pivot the conversation a little bit and talk about in particular deleting code and retiring services like when you've when you reach a point where it's time to sunset something because I know that you mentioned that there's some tools that may be written in other languages that nobody your company knows that well anymore and some of them might still be around but like for you what triggers that conversation about when it might be appropriate to sunset a service? >> That's an interesting question because there's I'm trying to think back and it's like there's been multiple kind of ways into that. Some of them have been as simple as we get a bill and you look at it and you go, "Well, that's a lot of money that we're paying to a third party service. Do we still need this third party service?" And maybe if we're larger, we got more people that can. It's not so much the service or the or the money, but the fact that we know that like >> that that lives in the code somewhere, right? And so if we can get that out of the code, that just makes the code base smaller and makes things easier to handle. The other side of it is like, yeah, we had a um a service that was written in um Phoenix Live View that was helping us do some I'm trying to think of the word for when you're doing the machine learning um and you're trying to train up the train up the models and doing like which image is the one that you that should have been chosen, that kind of thing. We had this whole thing that was supposed to we're capturing all that data, feeding it all back in. Uh, and you want to talk about bad naming, we called it Oracle, >> and it was being fed into, you guess it, a a BigQuery database, not an Oracle database. >> Um, but it was supposed to be like, you know, the Oracle Adelfi kind of thing. It was going to show us the future of of that kind of thing. And so when we downsized, the the folks that were not only responsible for working on it, but also responsible for kind of that whole segment of the business is just like, well, we don't have the expertise for it. What should we do about it? Basically costing us nothing, right? As long as nobody uses it, it's fine. It'll cost us a little bit to kind of like keep it running. So, it's not the cost at that point, but it's the overhead of knowing that it's there that anytime we need to do any kind of like some kind of backplane updates or GCP this or those kind of things, it's always kind of hanging around there. And so, the question is like, is this useful? And if it's not useful at our size, it makes it really easy to just go, well, let's just turn it off, right? Like, does anybody want to take responsibility for this? And if the answer is no, I certainly don't, right? And so, uh, you know, deleting that service, getting rid of it, stopping all of the the data that we were flowing to it, that kind of thing. It was, that was a real easy decision. There's some other decisions that have been a little harder, but what it comes down to is especially for us, we're so tight-knit and because we have product like right in with us. We still have engineering meetings to talk about engineering stuff, but the real meat of stuff is always product design and all of us. And so like we've had a couple of things where like we spent a lot of time developing a feature and you're looking at it and just like does anybody use this? And somebody goes I forgot that that was there. Okay well if you forgot that that was there we haven't touched it in a while. Then we can ask James our product manager and just say James like are clients using this? We have really good relationships with our clients talking to clients a lot. Maybe not all of them but like we've got a good subset of clients who will tell us when things are good and bad and that kind of thing. And we've got, you know, metrics that'll tell us how much it's being used. And so there is a certain amount of like maybe it stays there, but the second that product wants to do something and it's going to touch that thing and we go, we could delete it and save ourselves a couple weeks versus, well, I mean, we start touching it, we've got no idea what's going to happen here. Those decisions are much more easily made nowadays because we really just want to be tightly focused on the stuff that we're working on. >> Do you feel like your team celebrates subtraction enough? Yeah, I mean maybe too much [laughter] uh like like uh one of our front-end developers, there's a feature that he's been uh trying to get us to remove for a very long time. And it's basically like the editor that you use to write plain English tests for our tester community to execute. It's really old, really clunky, and it gets in the way a lot of times because we think in terms of like the automated side of things. That's where all of our focus is on. And then somebody will say, "Okay, but if we do this, we got how are we going to handle that in the plain English editor?" And he's just like, "We could handle it by getting rid of it." [laughter] Right? So, so there is like Yeah. I don't have to worry about everybody always thinking about like just additive. It's just great to see that come up in Slack where somebody says, "Hey, I just came across this thing. Can we delete it?" And if the answer is yes, yeah, I mean, we celebrate that. We don't maybe celebrate it outside of engineering as much, but we certainly celebrate it within Yeah. within the group. No, something I've been thinking a lot more about recently is like how teams that as you've touched on like your team's gotten smaller over the years and there's this kind of thing where like I think when people get hired at a point in a company where the company's growing so there's kind of an assumption like well we're making decisions based off of a future world where there's more developers but whether or not it's I'm going to say air quote ideal or not there's a good chance that future version of your team is a smaller version of your team than it is today and you're responsible for everything that you're adding right so that isn't to say like don't >> add stuff. I think there's a always this balance, but there's probably things in everybody's apps that you probably could subtract, but nobody's advocating for it enough. >> Yeah. Do that extra pass, right? It's so easy to forget, especially for us because we use the app, but we use the app our way. And like we used to have an onboarding checklist that you went through and you know, product thought it was a good idea because we had people coming in. That was back when we had a free plan. So people were coming in and had no idea what they were getting. They had no customer service. They had nothing, right? They were just like thrown into it. So we had a checklist, right? But at some point we decided that we didn't need that onboarding anymore. And it's like it's fine. It's fine to delete it, right? Don't fool yourself that like, oh, it's in Git, so we'll go back. Like it's not It is in Git. You can go back and get it, but you won't. Nobody will remember that it's there. But like the front end got rid of it, but I just came across it and it's still in the back end, right? So like we have deleted it, but we didn't delete it all the way because we were doing something else. Didn't think about it. I was like, "So guess what I'm going to be doing this [laughter] week is getting rid of that." >> You know, I know that you stepped into a a manager role as the company's evolved. So how did that shift your relationship with the codebase? >> Oh man, did it shift it. Um yeah, stepping into management is you got to exercise the pragmatist muscle so much more, right? And it certainly helps coming from obviously coming from development, right? Understanding the drive to see something through all the way to the end like sanding off every edge case, getting it all down, that kind of thing. So from what I found in the new job is like not just supporting the team but it's so much of the like now I'm empowered to say no more no to things that maybe product wants to do. um no to some of the things that that developers not want to do, but you see that you know you're having your one-on- ones with them and they're talking about like I'm having a hard time doing this and being able to say don't do that, right? Like it's fine. Me saying it's fine is like I'd love that, right? Because what I'm doing is I'm giving you permission to not think about that anymore. And that's just so different because I am not that developer. I am the developer who wants to make it work, make it right, make it fast. I don't care so much about the make it fast part, but the making it right thing is always the like what more refactoring can I do? You know, well, how much better can I make all of this stuff? It still doesn't read right. What can I, you know, versus the like, hey, we have a product and we got to get some value in front of customers as soon as we possibly can. So, walking that line, um, it just becomes very clear kind of at the management level where that line is. you know, we have really good um relationships with the rest of the company. So, I'm the one usually having those kind of conversations and I'm also empowered to tell the devs to just put that to the side. Let's just ship it, right? Like, it's fine. Are you comfortable with shipping it? Then let's just go like let's just get this out and get this in front of people rather than spending way more time than we need to trying to make sure it's perfect, right? you know, as your team has gotten smaller, when you think about may may or may not be in a hiring phase right now, but how do you think about the level of experience with Ruby on Rails specifically? Do you think is change? Do you feel like that's something that maybe in our previous conversation you mentioned that maybe like people you would hire people at Rainforest and you could teach them rails to some degree. Is that accurate recollection of what we had discussed there? Yeah, when we were larger even just like not when we were like 15 20 it's the like hire a great developer and they'll be great at developing and sure yes but also the thing that you need to watch and this is have we've actually had this happen where if you've got the time if you've got the that only really works if you've got support for that developer right they don't need to be mentored like a junior developer coming in needs to be mentored but they do need to be shown own the ropes when it comes to Rails, right? If you have no Rails or Ruby experience, you're coming from something completely different. They're not going to write stuff idiomatically. And like all of the llinters in the world won't tell you why that's a good idea. I I still get stuff from Reek where it's like I get this thing, I go to the web page to find out like what's wrong with the code. I don't know what it's complaining about and it just just tells me what's wrong with the code. It's like no, I need like how do I improve this? Like what's the what's the thing to do there? So having that extra help there, I mean you can do it through PRs, but mentoring through PRs is not good. I've done that. I've gone down that line. So when you're when you're small like us, there is a certain amount of like I would love to just hire the best developer that I possibly can. But right now, if if and when we hire again, I need to hire the best React developer I can or the best Rails developer that I can or the best ops developer that I can. I we just don't have the ability internally to support them and get them, you know, get them up to speed and get them writing good Rails code because good Rails code is different than and good Ruby code is different than good Rails code, right? All of that kind of stuff. And like if you've been with Rails long enough, right, you know that there's all of the not even the edge cases, but the like yeah, we kind of just don't do that anymore, [laughter] right? Like and so and like you don't want them you're setting them up to fail a little bit in that sense, right? And like there is learning in that, but like at the size that we're at and the position that the business is in, we need to we need to get stuff out the door. And then the other side too is like we did have some developers that were really good developers that we hired, came in and hated absolutely hated Ruby and Rails. >> So what do you do in that case, right? Like we we gave them an app like we gave Oh, we actually do have another like microser that they worked on. It's like it they did an okay job, but when you're looking at the code, it's only Rails in the sense that like it's using Railsy stuff, but like it's not written in a Ruby way. It's not written in a Rails way. And so now, same thing. It's like, are you going to teach this person a lesson through PRs? No. [snorts] But so then, can you find something else for them to do? Maybe. Not in our shop, right? Like, so you just got to be mindful of that, too. You just don't know >> when an organization is bringing in people that come from other tech stacks and they're maybe not as excited to work with Rails or Ruby and kind of see like well it's a job and and then but that often at least from my my my sense is that that's when a lot of other tech stacks start popping up in people's platforms when they're like well we can try these other things and I think it's great that you're allowing your team to experiment and play with different technologies that's an important thing for professional development but also So as you know you're living with the the results of all those decisions of being like let's be flexible and experiment a lot of things and but we're still at the heart hey we're going to be a Ruby on real shop this is the platform we're kind of sticking with and there's a couple of little outliers here but if you're someone's listening right now and they're in a growing team and they they are a little lax on that right now maybe and they think that's a good thing would you give them some thoughts on like hey maybe don't it. I'm not saying there's a right way to handle that because I think there's we've also seen good examples where people have a lot of different tooling in their platform and that works at the scale that they are and they maintain but not all projects need to do that and so what's where's that balance there? >> Yeah, it's it's interesting because yeah, I'm definitely not going to be prescriptive on this call because everybody's going to have their own tolerance for it, right? Like at the very least you should be thinking really hard about it, especially if you haven't done it before, right? If you're at that first step of like, all right, we've gotten to the point where we can hire a junior developer and train them up. We can hire somebody from outside the like ecosystem that we're working them in or that we're working in and getting them on board. You have to realize that just because they're senior and and they can pick up a language like you would not believe, that is not it's not enough to just throw them to the wolves. like you are still going to have to spend time with them getting them getting them trained up and then there is a chance, right? It's it's a small chance, but I mean it's not I know it can happen because I've seen it. It's like what happens if they're not super into it and then what do you do? And maybe your team is is growing big enough that like you're not really a Rails shop. You're just a you just have this app and you've got all kinds of stuff and you can move them. You've got enough teams that you can kind of move them around to. Maybe they'll love to do front-end development. Throw them on that for a while. Um, but yeah, I would just I would be more cautious for for those people who are just getting into that. If you've got a big team right now, you know, right? You know, what kind of tolerance you kind of have for that. The other side is like check your your like internal engineering culture, right? Like how are you hiring for that because that's going to I think really direct a lot of it too. You should have a sense of before you hire this person, not just their technical chops, but what are they like as a person and are they going to fit in and are they going to, you know, maybe come around to Rails after a bit because they gave it a shot or are they immediately going to shut down, you know, all efforts kind of thing. And like we've been really good at Rainforest at at hiring for culture, which is why I think our team is is kind of operating at the level that we're at. But it's hard right doing that kind of thing is it's easy to see if somebody can write well should be easy to see if somebody can write some code but it's it's very difficult to find out how they are at taking criticism of that code and you know being open to change and talking to product and you know all of that kind of thing. Out of curiosity, kind of circling back to the first question, what keeps you on rails? How do you maybe I shouldn't assume this, but do you believe that Ruby on Rails has been part of Ring Forest secret sauce? >> Yeah, I think so. Right. It's funny because we don't have like the typical everything is in Rails and all that kind of stuff, but even if it's not necessarily the fact that it's Rails itself, but that like h I don't even want to bring up the the recent controversy with all the with like was it the bundler and and Rails and Ruby and all that kind of thing, but I just read a a good article that [laughter] was talking about the quoteunquote good old days and their good old days was like my good old days of like the the Ruby and Rails community and that kind of thing. And there was something about those people how that started up that like that is the secret sauce that I feel like we have in Rainforest right now. Now you could probably take Rails out and put Django in or put some other thing in there and now we would be okay. But I don't know that you get the same the the same set of people who built Rainforce Engineering to where it is now without that kind of without that base. And then the mix of people that we brought in who just jived with it, right? Like even if they don't get Rails, that kind of thing, they're still just like, yeah, it's we're all just we're all just trying to do the best here, right? And like the big thing for us is like the no It's it's through the company. if we still have values. I'm sure we [laughter] do, but whether where they're enshrined, but that has always been the one that has stuck around. And so much of it is just the like we trust what it is that you're doing, right? But and we're not calling you out to call you out, but like if there are hard questions, we expect you to be able to answer them and we expect you to if you can't answer them, that's fine, right? We expect you to say that, go off and find the answer and come back. And there's just something about that that's really the secret sauce of it. It's not so much Rails itself, but it's like that whole community, the how that all built up originally and then how we hired kind of based off of that. >> That that resonates a lot with me as well. Jay, I'm curious like what thing that comes bundled in Ruby on Rails is the thing that resonates with you most? Is there one feature in Rails that you're just like like if you were to tell someone that you got to check out Rails, look at this thing. I mean it's it sounds stupid but just the fact of like when you hit Rails new there's a folder structure and that folder and like if you know anything about MVC we can argue about whether it is MVC or whatever right but like if you know anything about it you know where things can go and like that is that is it's ridiculous that plus the fact that like you know you can spin up the server and it's right there but like the feature feature it's like as much as I hate having to deal with poorly written like active record stuff like the OM in Rails is just it's so good, right? It's so good. You know, you can shoot yourself in the foot with it. You can do what we've done, which is decide that like the way to use active record is to write a giant SQL query that is like just a massive string and then invoke it that way, right? Like, but you can do that, right? if you get down to that level, but especially recently with like the advancements that they've made with the Aerrol, I think that's how you pronounce it, and like all the stuff that you can do of like building queries out um from there, it's just it's so nice, you know, N plus1's aside, but it's yeah, that's the thing. It's like if you've never used an OM before, and I mean back when we were back when we started, I certainly hadn't. That's where the magic is. And then kind of taking that step down too of like active model. I really like what's going on there. Being able to serialize things in and out get the column level wrapping things, you know, like that's really nice, too. I mean, that's really the thing. The OM is is the killer Rails feature for me. >> It was the first thing that got me excited about Rails. And, you know, 20 something years later, I'm just like active record. dreamed that I would have had something like that before in my prior era of software development. All right, Jay. Well, a couple of quick last questions for you. We've held you hostage long enough. So, is there a technical book that you find yourself recommending to peers? >> Yeah, I mean, I'll give you three. >> Great. >> Two by Avdigram, who I think is maybe one of the best Ruby educators out there. His Exceptional Ruby and Confident Ruby. Both of those books, I think they're available on the pragmatic programmers, but like just really changed my brain about how to work with Ruby, especially confident Ruby. >> It's a good book. >> Yeah. Which is I mean, you can take the Ruby out of it, right? It's confident whatever language you're using, but just just the thinking about structuring methods in that way has made just such a huge difference in my life. And then the third one is Michael Feathers working effectively with legacy code. That is another one that like I I can't remember how long ago that got recommended but just like >> it's a good one >> blew my mind just simply because of the what like one or two three concepts in there. the concept of the seam, the concept of the oh I can't remember what the when you're trying to like find kind of that like pivot point in the code that like will let you actually use that seam and then but the big thing is like breaking dependencies and all of the different ways that he has of breaking dependencies in the back right it's just yeah there's a lot that probably most people don't need at the beginning of the book but that last half of it with breaking dependencies is just I literally broke it out this week to deal with this payment processing stuff. I'm like, where where do I begin? [laughter] >> That's great. I'll definitely include links to all those books in the show notes for everybody as well. And um I actually interviewed both of them on maintainable, so I'll maybe try to include links to those as well or people can search for that and find those as well. Where can folks follow your work or keep up with what you're building online? >> We're trying to resurrect the rainforest blog. We actually just put a new blog post out for the first time in years. We got a lot of smart developers, right? So, we are going to start trying to to post more stuff there. And then I'm Jen on basically every social media thing. I don't really post on X or anything anymore, but Blue Sky, Mastadon, that kind of not a lot of tech stuff there, but [laughter] you will get a sense of me personally for sure. >> All right. Well, great. The people track you down there and this episode can be an excuse to write something on that engineering blog. >> Yep, absolutely. Well, with that, Jay, thank you so much for stopping by to talk shop with us today and yeah, thanks so much for sharing everything with the Ruby on Rails community. >> Oh, thanks for having me. It's been a pleasure. >> That's it for this episode of On Rails. This podcast is produced by the Rails Foundation with support from its core and contributing members. If you enjoyed the ride, leave a quick review on Apple Podcast, Spotify, or YouTube. It helps more folks find the show. Again, I'm Robbie Russell. Thanks for writing along. See you next time.
Video description
In this episode of On Rails, Robby is joined by Jay Tennier, Engineering Manager at Rainforest QA, where he's spent over seven years working across a long-lived Rails monolith and supporting services. They explore how Rainforest maintains their platform with a small team, and the practical decisions that come with that reality. Jay shares lessons from pulling microservices back into the monolith, why they wrap third-party services in adapters, and how they push analytics work to BigQuery instead of straining their Rails database. The conversation covers testing philosophy including "wet tests" over DRY abstractions, using dry-monads for complex service flows, and how celebrating code deletion has become part of their engineering culture. *[00:00:00]* – Intro and welcome to Jay from Rainforest QA *[00:01:12]* – What keeps Jay "On Rails" since version 0.13 *[00:04:52]* – Overview of Rainforest QA's platform and architecture *[00:14:40]* – React frontend in separate repo and API strategy *[00:22:28]* – Team size evolution: from 40+ engineers down to 7 *[00:25:35]* – Failed experiments and the dry-monads pattern *[00:32:25]* – Data retention policies and deprovisioning clients *[00:36:01]* – Lessons from pulling microservices back into the monolith *[00:41:39]* – Building adapter layers for third-party services *[00:57:42]* – Testing philosophy: preferring "wet tests" over DRY *[01:08:54]* – Pushing analytics to BigQuery instead of Rails *[01:17:31]* – When to sunset services and delete code *[01:24:01]* – Transitioning into management and supporting the team *[01:32:47]* – Is Rails part of Rainforest's secret sauce? *[01:37:14]* – Book recommendations and where to follow Jay's work Social + Web Presence LinkedIn: https://www.linkedin.com/in/jaytennier/ GitHub: https://github.com/jaytennie/ Twitter/X: https://x.com/jaytennier Bluesky: https://bsky.app/profile/jaytennier.bsky.social Company/Org Links Homepage: https://www.rainforestqa.com/ Tools & Libraries Mentioned Active Record: Rails ORM. (https://guides.rubyonrails.org/active_record_basics.html) BigQuery: Hosted analytics warehouse. (https://cloud.google.com/bigquery) Cube.js: API layer for querying analytics data (https://cube.dev/). DRY-Monads: : Structured success/failure flow. (https://dry-rb.org/gems/dry-monads/) FactoryBot: Test data factories. (https://github.com/thoughtbot/factory_bot) Grape: Ruby API framework. (https://github.com/ruby-grape/grape) GoodJob: Background job processor. (https://github.com/bensheldon/good_job) Q Classic: DB-backed job queue (https://github.com/rainforestapp/queue_classic) Redash: SQL-based dashboards and reporting. (https://redash.io/) RSpec: Rails testing framework. (https://rspec.info/) React: Front-end application framework. (https://react.dev/) Haml: Legacy templating engine. (https://haml.info/) Segment/ Mixpanel: Event tracking pipelines. (https://segment.com/) / (https://mixpanel.com/) 📚 Books Mentioned Books Confident Ruby by Avdi Grimm (https://pragprog.com/titles/agcr/confident-ruby/) Exceptional Ruby by Avdi Grimm (https://pragprog.com/titles/agrexc/exceptional-ruby/) Working Effectively with Legacy Code by Michael Feathers (https://www.informit.com/store/working-effectively-with-legacy-code-9780131177055) #rails #rubyonrails #tech On Rails is a podcast focused on real-world technical decision-making, exploring how teams are scaling, architecting, and solving complex challenges with Rails. On Rails is brought to you by The Rails Foundation, and hosted by Robby Russell of Planet Argon, a consultancy that helps teams improve and modernize their existing Ruby on Rails apps