We can't find the internet
Attempting to reconnect
Something went wrong!
Attempting to reconnect
Zhang Jian · 3.8K views · 63 likes
Analysis Summary
Worth Noting
Positive elements
- This video provides a practical, historical look at how a real-world company transitioned from legacy ColdFusion and Scala to Clojure for standard web services.
Be Aware
Cautionary elements
- The speaker is the maintainer of the primary libraries he recommends (Java JDBC), which creates a self-reinforcing loop of authority.
Influence Dimensions
How are these scored?About this analysis
Knowing about these techniques makes them visible, not powerless. The ones that work best on you are the ones that match beliefs you already hold.
This analysis is a tool for your own thinking — what you do with it is up to you.
Related content covering similar topics.

Ritz, The Missing Clojure Tooling Hugo Duncan
Zhang Jian

Datomic Cloud - Datoms
ClojureTV

The Taming of the Deftype Baishampayan Ghose
Zhang Jian
Exercism Summer of Sexp - solving challenges with Clojure
Practicalli
Composable Tools - Alex Miller
ClojureTV
Transcript
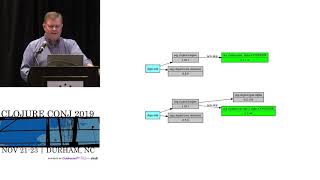
a lot of what we hear about closure is solving really hard problems and giant-scale and I want to talk about not that I want to talk about doing boring stuff building web apps and just using closure as a sort of general purpose language we get to hear about big data and analytics all the time we had a presentation on storm this morning we haven't had presentations on core logic yet I believe there's one this afternoon is that right lots of concurrency and massive scale subjects all hard problems and I think a lot of people out there get the impression that closure is really only good for solving hard problems you don't need to use closure unless you've got some horribly complex giant scale problem we've got to remember that the rationale actually says it's meant to be a general-purpose language and anywhere you can use Java you should be able to use closure and so we've taken that to heart at World singles we're an internet dating platform we're multilingual got about half a dozen languages live now we have 50 sites technically we have two code bases we have a legacy code base and we have a new code base that has closure in it and we're migrating all the sites over to it which is a lot of fun if you haven't heard of world singles I won't be in the least bit offended because we're all about little brands we're mostly focused on ethnic verticals not all of them some of them are more specialist interest but most of them are ethnic verticals so how did we come to use closure the company is actually historically a cold fusion shop how many people here have actually used cold fusion a surprising number of hands okay that that amazes me not I didn't mean it like that anyway um I joined World singles in 2009 and one of the things that we needed to get done was we have you know millions of member profiles and we have a custom search engine that we have to get all the data out of transform it to XML which is quite complex transformation a lot of business rules and post it off to the search engine it pretty much has to run 24/7 so we thought well we need to bring in something that's going to be faster that's just going to run and run so we actually started to look at Scala and we built a process in Scala and it was fairly active heavy and anyone who's used scholars actors in the 2.7 sort of 2.8 time knows that that was a bit problematic and in the end Scala wasn't really a good cultural fit for our team we had people who are used to dynamic scripting languages so I started looking at closure in 2010 my background originally back in the 90s was functional programming and I kind of watched in dismay that had sat on the sidelines I'd always wanted functional programming to go mainstream when Haskell came out I thought great here's a wonderful new language everyone's gonna pick it up will see people writing in Haskell and of course that didn't happen when Scala came out I was quite interested because we have functional programming again but f-sharp Haskell is now getting a bit more attraction and of course when closure came out I'm like oh good a dynamic scripting language on the JVM that gives me functional programming I tried out a few things it worked pretty well for some of our use cases some small examples and we actually went to production on 1.3 alpha 7 or alpha 8 in the middle of last year and since then we've just been doing a lot more closure how many people here are still on 1.2 okay not very many we jumped to 1.3 as early as we could so we've avoided a lot of the problems with the libraries that's a subject dear to my heart and I'm happy to talk about that outside to anyone who wants to listen and anyone who has got some suggestions how did we introduce closure we'd already got an established code base so we needed to pick small low-level components that we could start from the bottom and build up we wanted to take components and reuse them so that if we built code out in other languages we could reuse it across those as well as in our JVM based CF ml applications so we had to go down Jen class for a couple of things we have tried where possible to do everything through closure langar t so we essentially load up all of the namespaces we're going to expose into our code dynamically and just like close you get on with it that has the benefit that we can reload the application without downtime and it just picks up any new closure code and recompiles it so we can do deployments very easily we started below level we started with tools logging and log for J and that's where we head to gen class because we wrote our own app ender and environment control because we have all these different tiers and we wanted the configuration of the application to be automatic so those were things that we could pick on and move forward with and reuse in our tools where we are today is we do quite a lot of stuff with closure perhaps some surprising things here we generate a lot of rich HTML emails from the dating platform and we're using n live to generate templates it's all multilingual so we've actually written our I 18 n handling code in closure so that we can reuse that in C F and in the side components geolocation we use a mixture of databases and third-party services and we've wrapped all that up logging I mentioned persistence and the search engine interaction now I've only got 25 minutes I'm not used to giving talks after only 25 minutes so I will try very hard not to run long but that means that I can't talk about a lot of the things I'd really like to because I'm really enthusiastic about what we're able to do with closure so I'm going to look at just persistence and the search engine stuff because that's a mixture of fairly ordinary day-to-day stuff that closure actually has some nice libraries and idioms for as well as some interesting little problems how many people use closure Java JDBC okay so sequel database is not popular with the closure crowd I guess as part of the movement to closure 1.3 one of the things that I needed was a JDBC library and closure contrib sequel was sitting there on the old monolithic contrib and so I kept poking going hike and we get the sequel library moved over and poor folks said yeah well get to that it's on the list and I'd come back and go can we get the sequel library moved over please and they said do you want to do that and so I ended up maintaining it taking it over from Steven Gilardi it's nice but it's fairly low-level so what we did was we wrote a little crud wrapper so that we can just get my ID fine bye keys and so on and that has allowed us to write some fairly high-level code and work with the idioms of getting sequences of maps back from JDBC and then just running functions over them as we need them if you've used the JW C library at all you end up with this with connection and database and with naming strategy that's little ugly it's certainly a lot uglier than doing get by ID this API I asked core core approve all the Contra blueberries to go to a wander or release and they have given a laundry list of things that need to change in Java JDBC before it can go to a 100 release I think some of the points that are kind of interesting if there are macros being used for things like this with connection and with naming strategy they want to see a pure functional version where you don't have dynamic binding going on so it was a guideline for libraries basically everything needs to be able to done be done through pure functions so Java JDBC for those who of you who are using it is going to get a new API in addition to the current one that will be a lot more composable and a lot more functional the naming strategies are just ways of converting from keywords to entities in the sequel so for my sequel you have back quotes around things and we have plenty of column names that are keywords in sequel so we have to do that and for some reason the default behavior of Java JDBC is to take the result sets coming back from the database and lowercase all the columns by the time they come back into your code as keywords which sometimes it's not very convenient so you can specify a naming strategy that says please don't do that and when I get keywords back then I want them to be the identity of the column name so we have mixed case keywords we're also looking at moving some of our data to MongoDB now I got involved with Congo because again I wanted that on 1.3 and Congo is a nice wrapper again fairly low-level it turned out that the crud wrapper that we'd built for JDBC for a lot of cases would work for MongoDB all of the the gets finds deletes those sort of things apart from the pure execute of sequel would allow us to work with MongoDB using the same API and this was definitely one of the big wins for us with closure because it was very very easy to just modify our data layer to say oh is this table really a MongoDB collection and if it is then we'll do a fetch against otherwise we'll go to sequel and run the thing that you just saw and so now our application code doesn't care where our data is and in fact when we manage the relationship between objects at the application layer we might have an object come back from MongoDB that has foreign keys in two tables that are in my sequel that then has foreign keys back into something in MongoDB and the application just doesn't care the nice thing for that is that we are able to gradually migrate things from my sequel to MongoDB now there's a an eHarmony guy here I was chatting to one of the harmony folks Schuyler lift-off some time back and they were talking about moving from standard sequel databases to the no sequel databases at around I think it was three million records which is where we are and why we're moving so a generic application code can use these as I say we're not very happy with the function API here the the little having a function that gets passed in this is kind of a holdover from the Java JDBC with query results which is a macro then applies a function to or executes the body against the entire result set so because it has the open connection and you need it closed you pretty much always have to pass do all in there to realize it so we kind of went that way we're gonna change this it seems really ugly to have to always have do all in there for a lot of things if you just want the record set back and I know some people working with the JDBC library have kind of complained that you have to jump through some hoops just to do things like get single records back or a handful of records so if anyone has any suggestions on that amongst the users I would love to hear suggestions for improving the API of closure Java JDBC the search engine we use is called discovery it's by a company called transparency and it's really good for fuzzy searching it's improved over the years but it has a fairly strange way of interacting with it and the all data goes in via XML or it can pull it out of your database but now they have nice JSON queries so we decided that we would write the process that scans the database goes through the business rules traits XML create that in closure this was the code that we had in Scala we had about a thousand lines of Scala act based it had memory leaks so the process tended to fall over and we had to keep restarting it and we've gone through the whole 2.7 to 2.8 upgrade with Scala which was very unpleasant I'm seeing some nodding faces in the audience so by the time we got to this this ironically what we'd introduce Scala to do heavy lifting and is sort of the very thing that closure is always being praised for being very good at which is processing large amounts of data and it turned out to be relatively simple I like the CL J HTTP library because very easy just to post to some end point this is a standalone process so we're actually pulling options from Tools CLI and to process the users we run hiccup so you can see it's a change set there is just part of the XML route of the document we map render users render user across the set of users that have changed so again nice and easy we just write a function that renders users and we don't have to worry about anything else and then just post the XML so that was very concise render user has a lot of logic in it behind the scenes the overall structure of it says if the user is excluded from search then we'll send a remove packet otherwise we'll send a set item packet with all the properties and inside that you can see we're just doing map render item across the dimensions so we were finding that we were able to write lots of small composable functions that were easy to understand that really haven't been as easy to do in a lot of other languages and it performed well the query again nice simple stuff based around CLG HTTP that looks like a lot of code the important part is this with a JSON library take a closure map which is our search criteria just convert it to JSON post it to the search engine if we get a status 200 back turn that result back into a data structure and then the rest of the program merrily goes along its way dealing with closure maps and vectors and so on this proved to be very nice to just be able to process all of our criteria going into the search engine and our results coming back using map and filter and so on without a lot of complex code we'd had before with all those loops and all that imperative stuff back in the context of this if we actually get results back we go and get all the users from the database that match what we get back out of the search result and then we make it ordered query so that the vector the sequence of maps is in the same order as it comes back from the search engine and then the error handling again post using clj HTTP very very simple this time it's actually coming out of the application so this is where the environment control comes in we have M slash mail settings and something that we found we were using a lot is essentially Singleton's where the values computed once the applications up and running and then we needed to cached and so after asking around on the IRC channel someone said well why not just use a delay and it turned out to be a very nice elegant solution to something that is otherwise a bit of an ugly problem because we just say delay it until someone actually uses it we don't have to write any special access code we can just dear effort whenever we need the values and again a little bit of sequel I'm not going to go into much of the code around this as I say we've got all of these pieces put together now we're finding that by having these things as small composable functions we're able to move away from what has essentially been a monolithic web application and certainly a legacy platform was a large enough monolithic web application that we felt we had to rewrite it the new platform started out life heading towards monolithic web application but now we have closure in the mix we're moving much more to a lot of small processes that are able to perform tasks independently and to communicate with each other if necessary out of the context of the application itself so it puts us in a better position for breaking the application up into things that will run on small Amazon instances example rather than large servers things like the search engines still have to run on big servers with a lot of memory but more and more of the application is gradually moving into these small collaborating processes in the end we don't actually use a huge number of libraries from contrib we're only using the JSON JDBC the CLI library and the logging in a way I kind of wish we were using more of contrib because that would give me more incentive to try and get some of the older contract moved over it was one of the bonuses of coming in on the 1.3 curve of not having to deal with the legacy of 1.1 and 1.2 I know some people who are on those have said that the biggest obstacle to moving is contrib not so much the changes in the language itself a handful of closure libraries out there it's it's a weird mix the seem to be a lot of very small libraries in some cases doing similar things we use both clj time and date clj and that was historically we kind of picked up date clj first and I've actually ended up maintaining clj time McGranahan didn't have enough time to work on it and I volunteered but it doesn't just drop in and replace so I think navigating that big space of the closure third-party libraries is pretty hard there's a lot of stuff on closures there's a lot of stuff on github and finding the right tool for the job is sometimes rather difficult the json library i think there's three or four json libraries out there there's the standard one in contrib there are faster solutions out there that have fewer features there are others that have more features so I'd be interested to hear from people on advice on how to navigate that because right now it seems to move a minefield and then we use a few bits and pieces from Java this was actually the first time I'd had to deal with the Java mail API it's horrible I couldn't believe what I had to go through to send a simple HTML email fortunately of course now we have it wrapped up in a nice closure function and we don't have to worry about it but some of the Java libraries are horrible to work with so wrappers for those definitely valuable we don't have a lot of closure yet three and a half thousand lines isn't a huge amount but we found that we've got an awful lot done with it the thousand lines of Scala I mentioned for the publishing process we ended up replacing with 300 lines of closure that essentially followed the same algorithm it even had a lot of the same names of functions in it that was a bit of a surprise someone waiting posted it on Hacker News and I then had to spend 48 hours defending my claims that the closure was a similar structure and yet much more compact I will say that some of that was due to not having a decent sequel abstraction in Scala for our code back then I don't know whether that's improved but certainly the worsen library issues there we have what I believe is quite a large amount of tests for the amount of code we've got we've got about a 5 to 1 ratio between production code and test code how many people here feel that they do as much TDD enclosure as they did in other languages that's kind of what I thought very few hands so for most people you're not writing tests you're just not writing as many tests working with raffle more rather than tests writing more tests you gotta hand up it back yeah yeah you it I don't know why that the closure community has certainly got a bit of a reputation for not doing a lot of unit testing and you know there was Rich's talk we're talking about guardrails and that seems to have got taken out of context but it does seem that there isn't as much TDD being done and I don't know whether that's just because the repple everyone thinks the raffle is better but we seem to have a reasonable mount and just yesterday I found that was the first time I'd looked at expectations from J fields and I think we'll be switching over to that because right now we're using closure tests and we're using line multi test because we're testing against 1.4 so that we can move to it fairly soon and we'll switch to profiles in line again to anyone using lighting into already a couple of hands for us closure performs well it certainly performs well enough for what we're doing we actually don't use the adobe coldfusion product we use a JBoss community project called Rilo which is a very fast open-source implementation of CFM l so for the front end we've already got about as fast as we can go the closure process that does all of the publishing does not run as fast as the scholar process but it runs longer and that's kind of more important and doesn't use as much memory the immutable data has provided us with a thread safety which means we can just get on with solving our problems and not having to worry about heavy concurrency and objects and thread safety and objects that has proved to be a problem with some of the code in the past and we are actually using a third-party library for persistence which we're moving away from which has thread safety problems that's a cold fusion problem you guys don't need to worry about and certainly the maintenance and flexibility is pretty good the closure drives us to create much small components and we're finding that we're able to make some fairly sweeping changes to our business rules usually they're just swapping out functions and for some processes as we all do things like passing a map of functions to control how it should behave in different circumstances so the higher-order functions and that side of things prove to be really really good for flexibility we're training more of our team we've actually got two of our team here one of them took the kaskell of course our closure code to base is obviously growing it seems to grow a lot more slowly than some of our other code and we're looking kaskell up because we think that that will help us do a lot of the analysis the ad hoc analysis we need to do on the amount of data we've got and gradually we will be in that Big Data space the closure is so good at we're actually hiring which I think a lot of closure companies are and that puts me at about 25 minutes so that is my time I will take questions so the question was what are strategies for dealing with the closure contrib issue it's kind of interesting because there's a dichotomy between making contrib here for people to work on by having it broken up into small pieces that can then move forward on their own terms yet some people feel that by having to have a contributors agreement and having the name of the project controlled by core and the infrastructure with JIRA that it's it's an obstacle to getting things done I'm a little surprised if you go look at the wetted closure contrib page go on the wiki I'm actually quite surprised that there's so many pieces of old contrib that no one has stepped forward to maintain so I would say if you are relying on an old contrib and you rely on it heavily and you want to see it in the new contrib step forward and you know at least talk to the author of it or you know volunteer to be the maintainer know I think part of the problem with trying to do those sort of benchmarks is actually finding like things to compare because you know if you've got a dating platform web app isn't gonna look like something else unless you've got really common web apps that people are building in lots of different languages you're not going to be able to do that well thank you very much I will continue to take questions out in the hallway
Video description
from infoq