We can't find the internet
Attempting to reconnect
Something went wrong!
Attempting to reconnect
Analysis Summary
Worth Noting
Positive elements
- This video provides a detailed look at how to implement immutable, graph-based evaluation cycles in a real-world fintech application using Clojure.
Influence Dimensions
How are these scored?About this analysis
Knowing about these techniques makes them visible, not powerless. The ones that work best on you are the ones that match beliefs you already hold.
This analysis is a tool for your own thinking — what you do with it is up to you.
Related content covering similar topics.

Datomic Cloud - Datoms
ClojureTV

The Taming of the Deftype Baishampayan Ghose
Zhang Jian
Exercism Summer of Sexp - solving challenges with Clojure
Practicalli
Composable Tools - Alex Miller
ClojureTV

Understanding Core Clojure Functions Jonathan Graham
Zhang Jian
Transcript
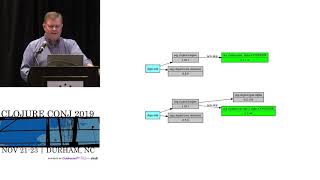
Good morning everybody. Um so uh just a little quick about me. Um uh I got introduced to closure about 10 years ago but uh my first exposure to lisp and functional programming was back in 1995. So as you saw how old I am. Um and I've really been kind of uh you know been two kind of paths in my career. one is functional programming, the other is uh distributed systems or systems in general. And this is kind of a combination of both of those things. So, um had a career in a variety of industries uh most recently in fintech. Uh and this is what I'm talking about today. Um and thankfully I'm not that far away, so I just drove over here. Um so I work at Splash Financial. Um we're essentially a middleman between lenders and uh borrowers and uh uh you know basically in three different areas, student loans, personal loans, and most recently in home equity lines of credit. We're a relatively small company about 40 developers. Um and uh about 150 people total. So what do we what are we doing at Splash really? Like what's really the problem? So I think one of the key aspects of this that makes it different than a lot of other things I've been in before is there are very high consequences to getting it wrong. Um you make a loan for half a million dollars to the wrong person that has a big deal. So um we don't have that much high throughput but there's a lot of risk involved and and most of the data we deal with is highly sensitive. So being very careful with that data is very important. Um and you know part of getting it right is uh you know having reliability and correctness in terms of the computations you do and also audibility of what possibly went wrong if it did went wrong and knowing how to correct it. Um and then the last big challenge is that there's a constantly evolving market out there and um we need to be able to try new experiments about how to different have different behaviors in the learn process and be able to do it in a way which is safe and doesn't break things that already work. Um and so that drives a lot of the design behind this. So um to save a lot of time I'm going to assume that you basically agree with this. I know that there's a lot of gray area in some of these things, but uh you know, with 30 minutes, I don't really have enough time to get into all of this, but uh just to say that fire is very much on the good side of this. Um and it's it's a variety of event sourcing in CKS. Um I'd say it's a kind of evolution of that in my mind. Um this is my I think fourth time kind of getting into this area, but for those of you maybe not as initiated as much into all this, just a quick primer. Uh event sourcing is the idea you have a set of facts from the world. You have some sort of computation that uh updates a kind of aggregate state. You can think of this is basically just reduce enclosure. Um you carry your state along and that state is completely derived from the combination of your input uh facts and uh pure functions, right? U which is nice because you can change your pure functions and re-evaluate. Um you have a full history of everything that's ever happened. um has a lot of strengths. Um, and simply I could get into a lot of details about this, but CQRS is basically the idea that you want to separate the part that deals with incoming novelty and doing that kind of computation I was just talking about from the part where you're trying to query or look at different combinations of your of your your data and have those in different subsystems um often connected by events or Kafka or something like that. And Fire has this kind of architecture as well. Um okay so what are drawbacks of this or things that that maybe motivated fire to try to go beyond that basic formulation. So the first one is that when you have one of these um kind of processes like this, you end up having to pack a lot in these green boxes at the top and often times that leads to FSM or like state machiny kind of mechanisms and you get to a place where that becomes overly complex and hard to reason about. Um you may have a a variety of different input events. They're not all the same kinds of things, but you have to represent somehow this cumulative history and some sort of enumes or you know things like this and it just it can quickly get out of control. And what splash does there can be hundreds of these kind of like interactions of things. Um the other is that if often times uh not always but oftentimes these systems tend to have a kind of streaming basis to them in which different aspects of the state are located in different deployed services and this makes it difficult to understand difficult to debug um and just difficult to operate to change um so it has a lot of strengths in terms of um performance and scalability but it has a lot of drawbacks too uh that I I think has made some people be cautioned to get into. Um, so how's fire different? So what is fire? This is just a little, you know, acronym we came up with. We wanted to call it something like MNTA, but the management didn't like that. Um, so we had to come up with this. Uh, turns out it's nice and slack because you can use a little fire emoji on things whenever something's deployed. Um, okay. But what is it really? So um, the number one thing is that those green boxes at top are no longer just like some map. they're actually a graph. So what's important here is that we represent um a process as a set of these pure functions. Um but there are explicit steps between them. So we know like when new data is input and a series of computations have to happen, we know exactly which data flows through which steps. It's not just mysteriously because the functions happen to call each other. We have that codified as a data uh centric thing. Um, and the other thing is that this is a reactive process. So, um, observations, I'm going to use some fire terminology here. My apologies if this overlaps with other people's words, which don't mean the same things, but I'll try to clarify. Um, observations for us are just straight ground truth facts, things you measure from the outside world. So, this could come from our customers, this could come from our internal underwriters making decisions about things. Uh it could also come from external data services like credit reporting or income reporting or other things like that risk reporting of various kinds. Um and one of the important things about fire is that we've centralized all of the uh business logic computations and the event um store in one service. So it is kind of a monolith in that sense. Um but our experience is that we can do graph evaluation in a matter of like hundreds of milliseconds, low hundreds of milliseconds mostly. Uh we don't have scalability issues. We're not going to handle more than a you know single digit thousands of applications a day, not like hundreds of thousands a second or anything. So this works perfectly well and our experiences probably could scale to very large numbers. Um but let me just show you a little example of what it looks like. So this is sort of the very high level of how fire works. It starts with an observation that comes in from the outside world. Uh there's a graph evaluation. You can think of that observation as being the leaf on a tree. And then whatever is downstream of that leaf gets evaluated. And that collection of both the observation and any derived events that are created along the way we store together in a transaction in a database. Um that kicks off a process. The response to that is we update a set of leaves that we would like to go acquire. So one of the the kind of key ideas here is that imagine the loan process where the root of the tree and this is tree theme for this year um is our decision about the application. So uh we either accept it or deny it let's say in simple sense and but we could be in this intermediate state which is we know something about the application but we don't know enough to go either way yet and so the trick is what do we need to go gather from the outside world in order to make progress on that and so the graph has this interesting characteristic it's not just one way. Um each node in the graph in addition to returning value also returns which of its inputs it would like to have fresher values on and we kind of backwards trace that up to the leaves and use that to drive to ask the front end what to go do. Uh similarly the observer services which are um kind of microservices that are responsible for interacting with some sort of data provider from the outside world also communicated through events called commands which drive that kind of interaction. So, it's kind of like a a rinse and repeat sort of process. We get a new observation, we evaluate it. Did we get to some sort of conclusion, okay, we're done. If we didn't get to some conclusion, what do we need to go farther? And then we just kind of keep going, right? So, here's a little more detail. I hope this is readable this. Um, so you can imagine we start with this blue observation here that causes some evaluation downstream of it in the tree. Uh, these green nodes we call inferences. Um and then all these things are committed as this transaction as I was saying before. Um um and then here's another example. We get a second observation. It creates another generation here, generation two, so on and so forth. Um, one of the really interesting aspects of fire and and in some ways I think it was it was sort of in our design but I think in practice we realized it was much more powerful and useful than we thought at first is that the evaluation of any of these nodes which are just pure closure functions basically um could potentially throw an exception and you can use that exception throwing as a way to signal that the input of the observation is not what you want. So for instance, you could use it to say the loan has gotten to a certain place where we don't want to accept any changes to your credit profile and if you try to make more observations like that, we will just say no thank you and that whole transaction will not be committed to the database and it allows us to have a lot of event sourcing systems have this characteristic of they can't really control what comes in. It's just a whole pile of things come in then they have to react to it. This allows us to say beyond the normal validation kind of constraints of like it's a malformed image event or we don't know what you're talking about. We also have well actually you picked a loan amount that's outside the range that we already said that you needed to pick so we're not going to accept that right. Um okay so going forward this is sort of like highle taxonomy of fire events. So I've talked about observations and inferences. Um there's actually a couple other flavors I won't talk about but maybe questions in the hallway. Um the other one we should really talk about is commands though and how we handle asynchronous and side effecty uh kinds of things because we keep all side effects out of the graph. So when a graph evaluation happens there's no external communication with the outside world. Um and the only real communication is just the state from the database and writing to the database at the end of the transaction. Um what commands allow us to do and I'll show you an example here is to capture the information necessary to go do a side effect. So uh in this case we get this new observation the blue one. Um now the the function for a command is a little bit different than an inference in that it can decide not to produce an event. Inferences always produce something. It could be nil you know but like commands basically can say I don't want to do anything or they can produce a command event and the command events uh value is essentially um the information that's going to be necessary for a handler to go do something with right but like every other evaluation we create another generation it's put into our event store we return back to the caller by the way that observation thing is a synchronous HTTP call so you you say here's my new observation and you get back that information about what new observations you might want in the future. Okay, so we also have debzium kind of in this that's takes these events off of this is in Postgress puts them into Kafka and then we have these observer services which are Kafka consumers and they have handlers that look for specific kinds of events. So this could be like say our transunion uh credit reporting service for instance. Uh it goes and makes this any kind of external communication it needs to do and then uh as a consequence it makes an observation and that restarts the process again. Right? Um so uh I'm going to show you an example of all this in just a second. Um but just a few things about the process. Um last November about this time we started implementing this. Uh this is the architecture and building a new product. Uh as it we had a relatively small team. We managed to build a new product that we launched in the spring uh in about 7 months. Um it was remarkably more productive than our previous architectures. Um and since then it's had great performance. It's had essentially no uh significant production incidents. very minor things. Um, and uh, it has a level of security which is very high compared to our previous ones which I'll I'll maybe talk about at the end. So I'd like to do now is show you an example of a tool we have called Hydrant uh, that we use internally. And this is sort of our our extension to the ID, you could say. So uh, let me uh, back up here for a second. Sorry, this is a little bit hard with the touchpad, but uh so zoom in a little bit. This is sort of the root of the tree of our helic application thing. So this is in our staging environment. This is the real thing. Um and we have these nodes at the top which are kind of like the conclusion, right? And you can see that they have a bunch of different uh things that flow into it. And these orange lines are that kind of acquisition log like I was talking about before. So essentially what it is saying is this taskmaster is saying like I still need you to do confirmed declarations and your employment stuff and deal with the offers. Um I don't need you to do these things up here that are black. Um so let's just follow a pathway all the way up to the and see what it looks like. Right? So I won't bore you with exactly everything along the way here and it's pretty involved. But eventually uh we get to something like this which is like okay well we need your date of birth still and we still need your phone number in order to go get the credit report. So this is the command note. We can see it hasn't uh been clicked yet. And if we look on something that we already have a value for here um fans of portal might recognize this. Um so we can inspect the data uh for any of these nodes. We also have this other panel on the left which shows us the history of all events that have happened. Um, and this is the current generation that we're in. Um, and if you scroll down here enough, we'll you can see these black boxes are where events occurring. And up here in the top or these blue ones are the observations. And down here, you can see there's some of the inferences and uh, finally commands. So let's go back and I'll show you what it really looks like as we make progress on this. So this is the actual application. So what it looks like when you're I've I've fast forwarded up to this point so we can get faster through it. Uh but you can see that actually I'm providing three different kinds of information here. Date of birth, phone number, and this consent. And in fire, these are actually separate things. Um zoom here a little bit. So there's the consent, there's the date of birth, uh there's the phone number. um we have them separated so that the UI can reformulate these things at will without us having to worry about that. So we're very very decoupled from the front end. Um which I'll explain a little bit more in a second, but like uh let's go ahead and do this. Oh, that's not good. Maybe just because we're uh the network's been a little janky here. Okay, sorry. That's why I saved this link. Hopefully, this will get us back. Oh, man. All right, I might have to uh handwave on this a bit. Uh, how much time do I have? Okay, let me uh try to jump in real quick. So this is a little tool we have called Marshall that allows us to do like testing and stuff like that. And so I'm going to go ahead and create a new application here and try to speedrun through this a bit. This we have this test user called Nancy Burkehead. Don't ask me why it's called that. Uh, I'm sure there's a real Nancy out there somewhere. I apologize. Um, wait a minute. I got to grab some information here real quick. always fun for the uh conference network here. Right. Got that some of this stuff full time employed. See? Okay. Okay, I think we're about back to where we were here. Um, okay. Maybe easier for me to paste than screw it up on a I don't know. Typing on a laptop keyboard is just never a good experience for me. Uh, this can be anything. So, we can All right. So, here's where we should have been a minute ago. And if we look back in here and hydrant Oh, it's going to be a different user. So, it's a little bit of the secret sauce here. This part of the URL is actually the go for the uh kid me here. Oh man. Yeah, I'll just do that right now. I got to navigate back to it, though. Uh, let's see. The quickest way just start here, I think. Right. Okay. So, we see we've created the command here. Uh let me uh jump in real quick. Look at that. And you can see it's kind of a collection of the information that from its inputs that were necessary to fulfill this. And that caused the ser the transfusion service to go make this observation here. And this little dotted line is sort of saying this is kind of like a leaf really this note I'm looking at. Um the dotted line means there was this asynchronous kind of pathway that was happening in between those things. And if we look in here, we got a bunch of details about the credit report and trade lines and all that kind of stuff, right? So, if I open this up more, we'll see that we've filled out more of this graph. And if we go back to the application, uh I'll just pick some of these things and fast forward a little bit here. Uh say maybe 400,000. And so here's where we're actually offering the rates. So, we've done all the pricing calculations. Um, the first step in this is, uh, people put in what total amount of money they're going to draw because they don't have to draw all of it at once. And then we figure out all the interest rates and all that kind of stuff. And, uh, we premputee all this like a lookup table. So, it's really fast from the front end. And you might even notice it's like changing interest rate as we the amount of money because we have different adjustments at different things like that. So there's a lot of computation that's happening in the back end to kind of support what's happening here that's in that graph. Um and if we pick one of these things um you know we're getting farther into the process and I can go back to hydrant here and we can see kind of what's happened. Um one of the really nice things about this is it allows us to to really inspect in detail every aspect of this. Right. Um, so I'm just going to jump all the way here to the end so I can see this. But you'll see now, um, me update refresh the confirmed offer is no longer being acquired. Um, and so the we have this very loose coupling between the front end and the back end. Basically, the the back end says, um, here's the things I still want to know, and the front end decides, well, what order should I present those? um and how should I group them and how should I arrange that and the back end doesn't know or even care about that the order that the front end provides those observations could happen in any order and the back end will happen just or process it just fine it's written in such a way that it does and that allows us to do fast iteration on the front end without having to have any real coordination with the back end in fact it was so ridiculously decoupled that I think at the time of launch we had never actually run the front end and the back end together. Like the front end developers didn't need the back end, the back end developers didn't need the front end. We were just like kind of plowing ahead. Um more recently in about a month ago, we managed to get that all working. But um it's funny that we didn't need it, you know, like it uh um so uh whatever time I've got left here. Let me see. Quick time check. Um so there's a lot of Let me jump back to slides for a second. So there's a ton of stuff I don't really have enough time to talk about but I just want to mention that right um we have we use Mali to define all the attributes and we do it in a globally namespace way um we have not just uh the validation associated but we have uh data classification so we say how sensitive it is um and also documentation attached to that and these attributes are used across all events so when you see that attribute you know what it is across all the events that are created Um we have end toend uh envelope encryption of the data of the payload of that. So whether it's sensitive or not we protect it as if it was the holiest of holies that happens in the database and in Kafka. Um we can do local development with fire because we have uh pluggable modules for all the pieces of it. We use integrant to put this all together. Um we can replace the postgress database with an in-memory map atom kind of approach to things. And because of that we can run the entire uh basically logic of our whole system in a test or in a ripple. Um also our whole thing is specified with like data specifications the nodes and the graph structure and all that kind of stuff. So you can write a test like instead of having 50 nodes I want these six nodes and I want to stub out the inferences for some of the leaves with some test observations and I want to run that in my test and do a generative test on it. allows us to do like very fast um very exhaustive easy cycle. You really could disconnect your laptop from the internet and do development all day long without any problem. Um we have staging environments and stuff but we don't really use them as much as we do local development. It's probably like 80% local development. Um it's also a great debugging tool. Hydrome. So uh the day we released it on the first day we had a bug. Uh we found out what it was. I'm not joking. In 10 minutes, uh, we jumped into the the graph, started following through the graph. Yeah, that looks right. That looks right. Okay, it all looks right. What's the front end doing? And it turned out it was a a mistake in the front end. They got it kind of wedged in the state. But, uh, you know, it was very easy to figure out where the piece of code was, where it was. Um, uh, already talked about testing. Um, oh, this is a big thing. probably can barely test talk touch talks about it but like our code is immutable too. So when we release a node into production we the source code is in it own namespace and we never touch that name space again. The only the example we would touch that if it was broken doesn't work at all. Uh but if it's in production it's going to stay that way. If we need to make any changes it's like we're making a new major release to a library. Uh we treat it internally that way. Um, this means that we know that any graph that's any application that's in production is using a specific version of the graph and we know that it will continue to behave like that forever and can't be broken by any experiments or new approaches that we're doing that allows us to have this kind of experimentation kind of for free like our whole backend infrastructure you could say is versioned. Um, and so simultaneously we can have multiple approaches to things going on. we can do AB tests but um the whole thing not just of a whole feature but like the features only it's like the whole graph um very interestingly and this is one of the things I'm most proud of we developed hydrant very early in the process like in the first month or so of development and we used it throughout we used it to develop these graphs with product we would sit in a zoom meeting and actually literally be building the graphs in hydrant while talking through the problems with them the nodes in these graphs represent business significant events They're understandable to product and business people. They're not a mysterious black art that only the developers know. Um, and then uh a last thing that we haven't really fully implemented to the degree that I would like is all that stream of Kafka events we can use to do projections. We can use to do things like inventory management, reporting, analytics. We already send all this data into Snowflake and use that for data warehouse stuff. But we have a lot more applications along the way that will be using the exhaustive. And uh that's basically it. I just want to thank the people besides me who contributed to this and there's quite a few. Um a lot of the people who were involved in the design were also involved in the implementation of it. But it was really a whole company effort. Um and we took quite a long time. I think this is a great example of how if you spend seven months of time doing design, you can spend a month and a half doing the implementation and it works really well. Um, so that's it. Thank you. Thank you, Jim. Uh, we do have a few minutes for questions. There's a mic up here if anyone wants to uh walk up and ask a question. Um, feel free to ask Jim all about fire architecture or another burning question on your mind. >> So, Hydrant looked brilliant. That was excellent. What What's the basic tech behind the front end of of uh what you're just >> uh it's closure script. Uh I think we use a a TypeScript library to do some of the graph drawing. But, uh you know, portables embedded in it. You can see um yeah, it's uh we just kind of designed it from scratch uh to meet the needs that we thought we would need in order to understand this stuff. I have to say uh if you look at the namespace that defines the edge list for these graphs, it's like you know about two and a half pages long worth of it's mind-numbing like without this you would not be able to understand it. Well, I think this is almost like critical to have this kind of tools in order to to do this kind of work. >> Okay, we have time for one more question. Go ahead. >> Uh thanks for the great talk. I'm wondering you mentioned every node is versioned uh as you build up. Is there a way to decommission old versions or eventually clean up the code that is no longer used in production? >> Uh more theoretically than practically. Uh we haven't had to yet because it's early days, but uh we have been thought thinking about that for sure. And uh I I didn't really talk about it, but we have a lot of things built into our CI/CD system to ensure that you didn't break something too. So for instance uh we generate a whole bunch of uh example applications run them through the graph of a certain version record those events store them in S3 use them later to when you produce new versions to make sure no one messed with some function that was a dependency of something that changes behavior. It's not perfect but you know it's also the way we've organized our code helps to uh make it easy that someone might make a breaking change right um so uh uh each node has its own namespace if you're editing that namespace and is not like new it's pretty clear you're doing something wrong to start with um so eventually to more directly answer your question we can do analysis on the events that are the applications that are still in flight what nodes are being used we can figure out what nodes are no longer being use and mark them as deprecated and eventually remove them from our codebase. We could do even offline events out of our database and put them in cold storage and stuff like that and have a backup to read from S3 or something like that if we ever need to rehydrate them. >> All right, one more round of applause for Jim Callahan. Thank you.
Video description
After 12 years of rapid product development as a broker, underwriter, and refinancer of consumer loans, our company found itself burdened by significant technical debt. This debt had become a substantial drag on engineering velocity, increasing the cost and complexity of delivering new features across our platform. When we set out to build our third major product—a Home Equity Line of Credit (HELOC)—we took the opportunity to rethink our system architecture from the ground up. The goal was to address the most critical pain points of our legacy systems acceleration future innovation. In this talk, we’ll share the design of our new architecture—known internally as FIRE—which features an append-only immutable event log, novel graph-based evaluation/acquisition cycle, complete separation of asynchronous I/O from synchronous strongly consistent pure-functional graph evaluation, loose coupling of FE/BE systems, ability to simultaneously deploy and run any number of different products or product versions side-by-side. Using our real-world HELOC product as an example, we'll explore the features of FIRE using Hydrant, our custom graph/event visualization tool. This tool has been an invaluable enhancer of collaboration between product and engineers, as an extension of IDEs for developers, and to track down and fix problems in production systems. Biography With over three decades of experience in functional programming and distributed systems, Jim Callahan brings deep expertise to modern event-driven architectures. Over the past decade, his work has centered on building reactive systems leveraging immutable data structures and pure functional evaluation, primarily using Clojure in cloud-native environments often using Kafka. At Splash Financial, Jim has led the design and implementation of the company’s new FIRE architecture—a cutting-edge, event-based, graph evaluation platform. As the most senior engineer at Splash, he served as technical lead for the launch of their new HELOC product, the first offering built entirely on FIRE. He now leads the company-wide initiative to modernize all products using this architecture. Recorded Nov 14, 2025 at Clojure/Conj 2025 in Charlotte, NC.